Monday


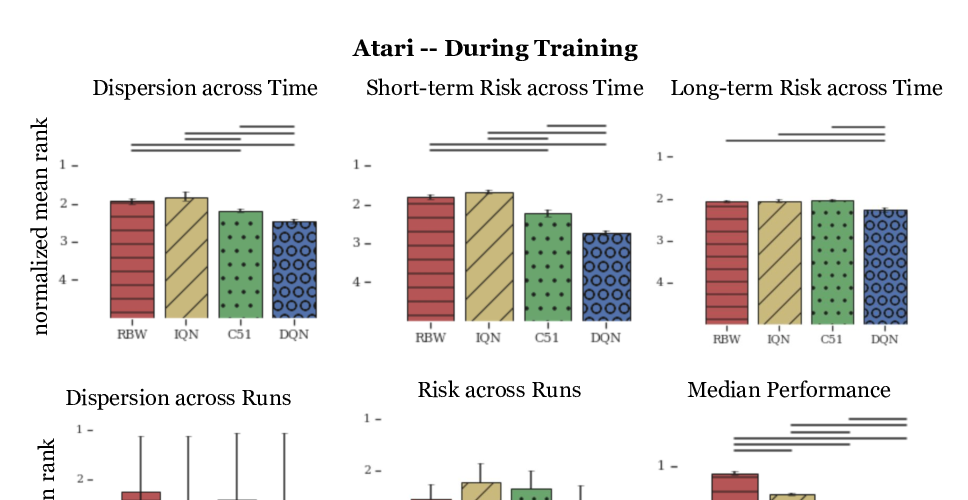
Measuring the Reliability of Reinforcement Learning Algorithms
Stephanie C.Y. Chan, Samuel Fishman, Anoop Korattikara, John Canny, Sergio Guadarrama,
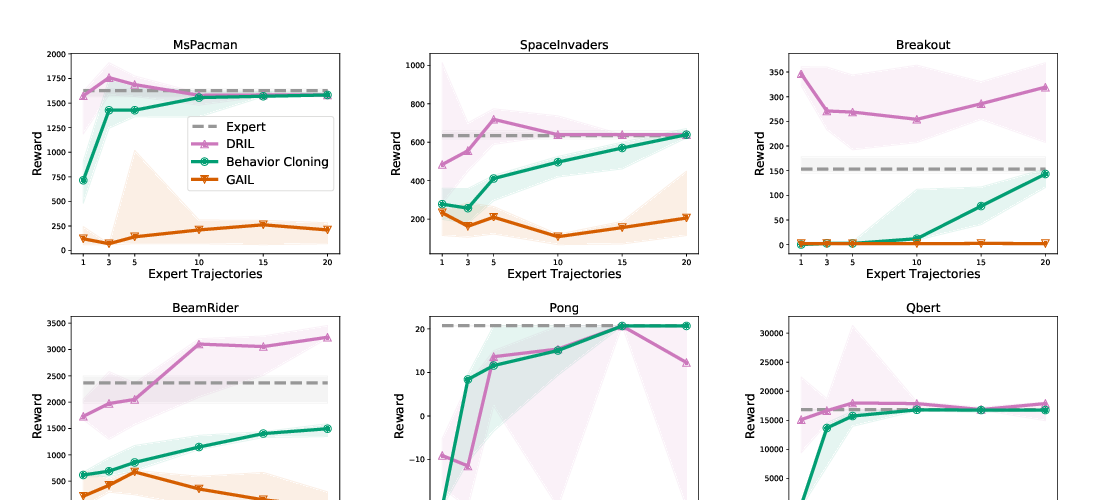
Making Sense of Reinforcement Learning and Probabilistic Inference
Brendan O'Donoghue, Ian Osband, Catalin Ionescu,
The Ingredients of Real World Robotic Reinforcement Learning
Henry Zhu, Justin Yu, Abhishek Gupta, Dhruv Shah, Kristian Hartikainen, Avi Singh, Vikash Kumar, Sergey Levine,

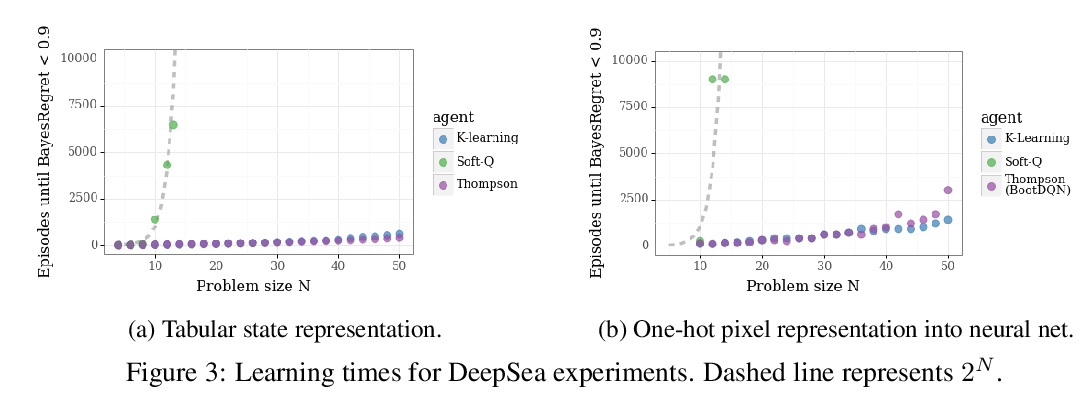
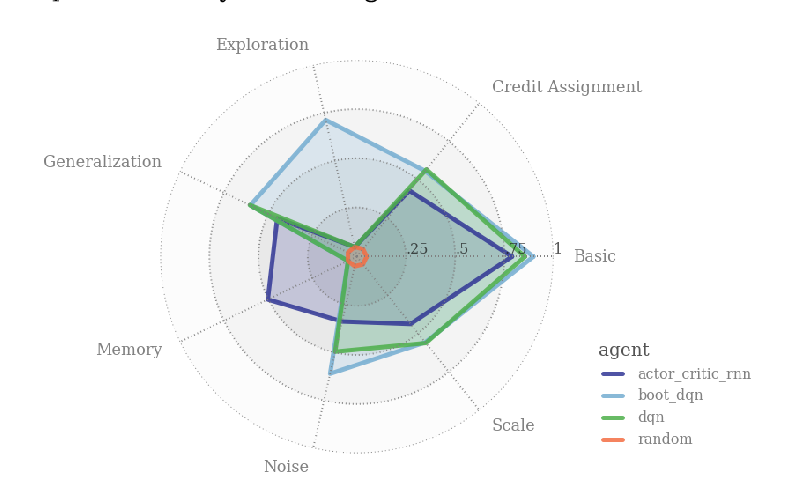
Behaviour Suite for Reinforcement Learning
Ian Osband, Yotam Doron, Matteo Hessel, John Aslanides, Eren Sezener, Andre Saraiva, Katrina McKinney, Tor Lattimore, Csaba Szepesvari, Satinder Singh, Benjamin Van Roy, Richard Sutton, David Silver, Hado Van Hasselt,
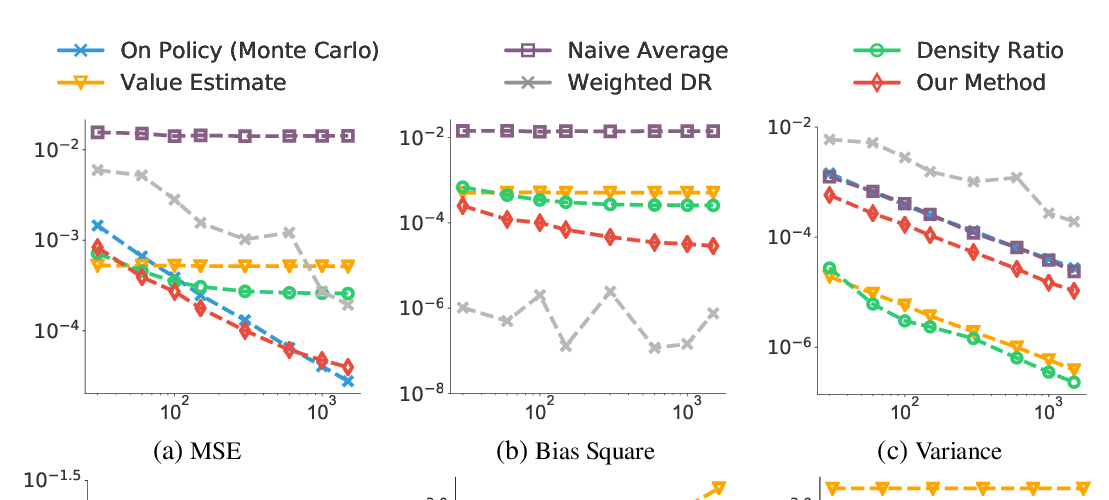
Doubly Robust Bias Reduction in Infinite Horizon Off-Policy Estimation
Ziyang Tang, Yihao Feng, Lihong Li, Dengyong Zhou, Qiang Liu,
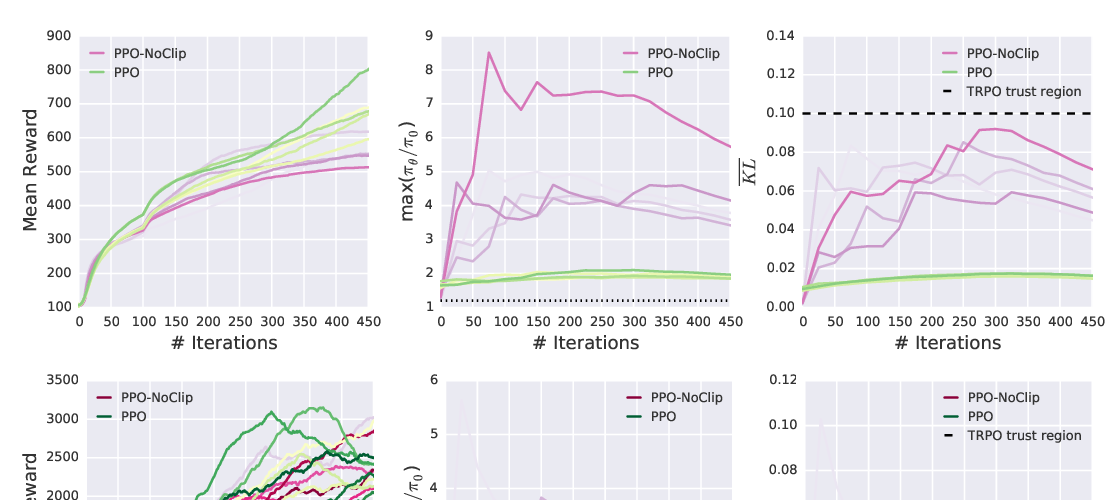
Implementation Matters in Deep RL: A Case Study on PPO and TRPO
Logan Engstrom, Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Firdaus Janoos, Larry Rudolph, Aleksander Madry,
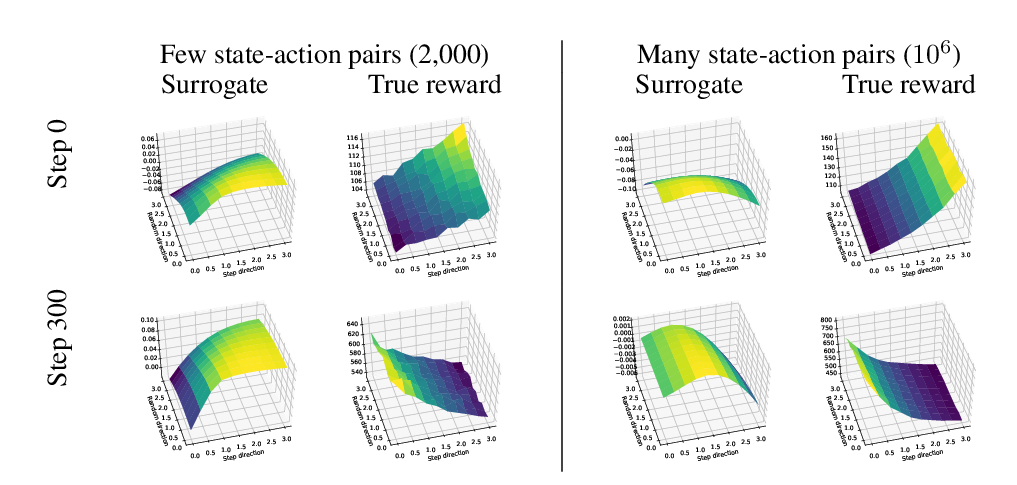
A Closer Look at Deep Policy Gradients
Andrew Ilyas, Logan Engstrom, Shibani Santurkar, Dimitris Tsipras, Firdaus Janoos, Larry Rudolph, Aleksander Madry,
On Robustness of Neural Ordinary Differential Equations
Hanshu YAN, Jiawei DU, Vincent TAN, Jiashi FENG,
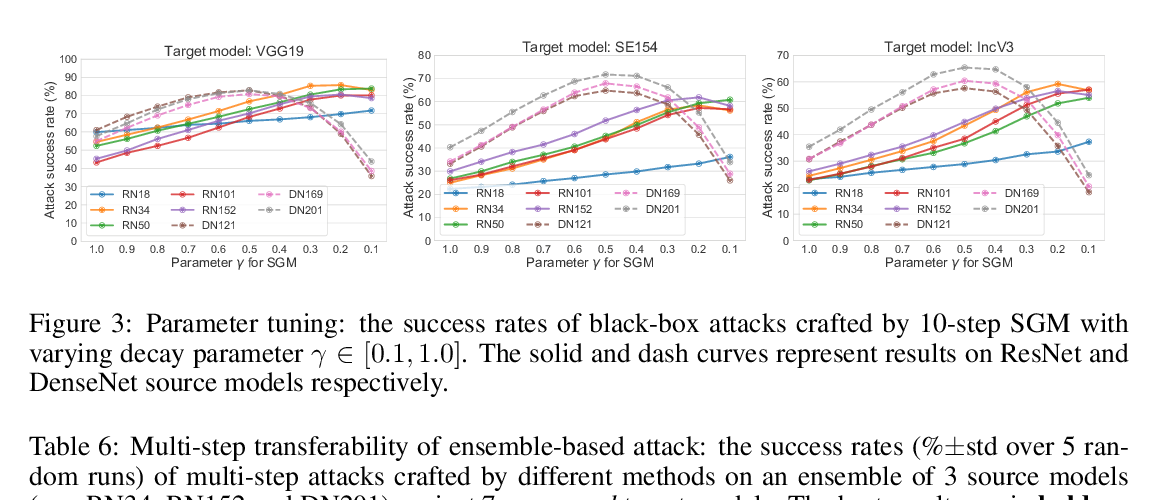
Skip Connections Matter: On the Transferability of Adversarial Examples Generated with ResNets
Dongxian Wu, Yisen Wang, Shu-Tao Xia, James Bailey, Xingjun Ma,

Defending Against Physically Realizable Attacks on Image Classification
Tong Wu, Liang Tong, Yevgeniy Vorobeychik,
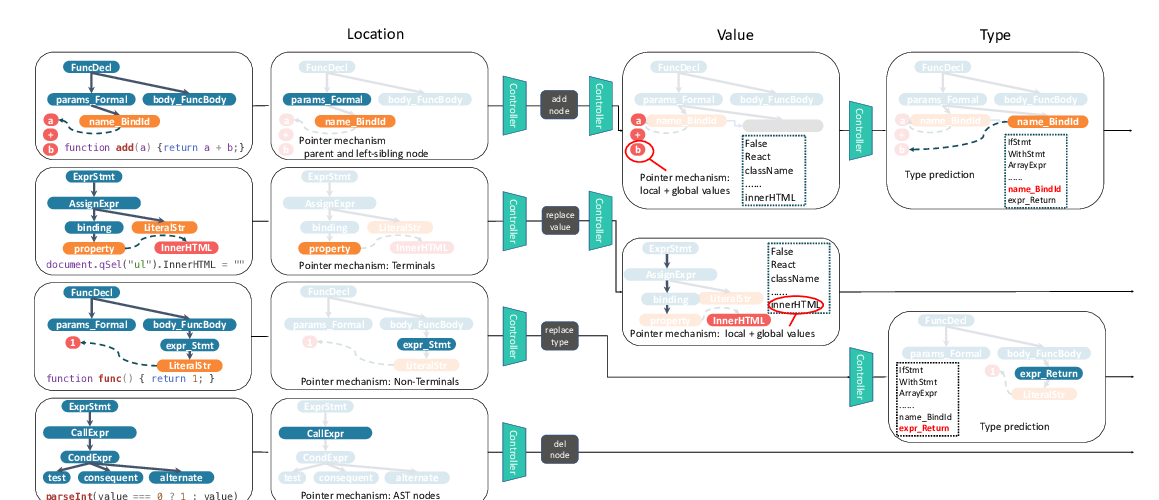
HOPPITY: LEARNING GRAPH TRANSFORMATIONS TO DETECT AND FIX BUGS IN PROGRAMS
Elizabeth Dinella, Hanjun Dai, Ziyang Li, Mayur Naik, Le Song, Ke Wang,
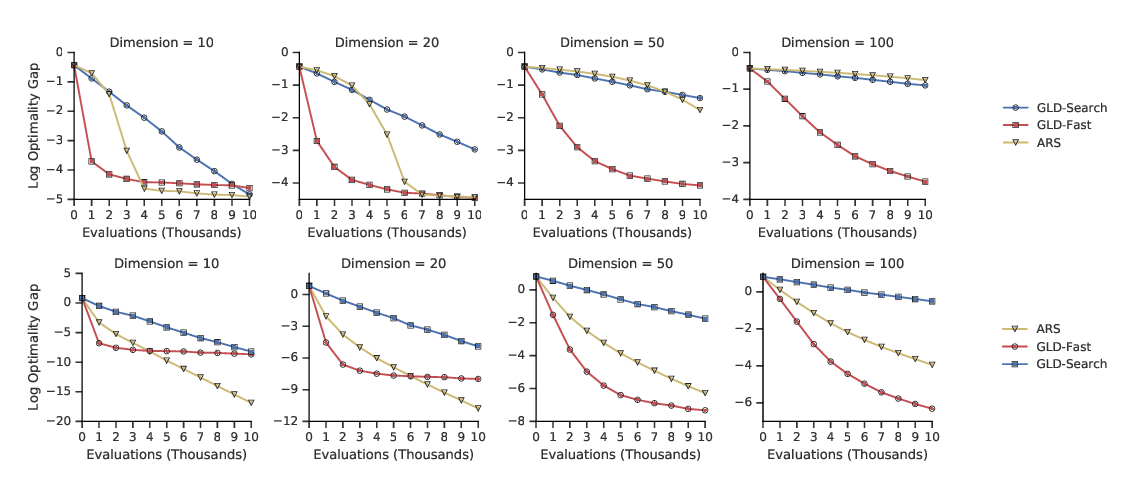
Gradientless Descent: High-Dimensional Zeroth-Order Optimization
Daniel Golovin, John Karro, Greg Kochanski, Chansoo Lee, Xingyou Song, Qiuyi Zhang,
Generalization of Two-layer Neural Networks: An Asymptotic Viewpoint
Jimmy Ba, Murat Erdogdu, Taiji Suzuki, Denny Wu, Tianzong Zhang,
Depth-Width Trade-offs for ReLU Networks via Sharkovsky's Theorem
Vaggos Chatziafratis, Sai Ganesh Nagarajan, Ioannis Panageas, Xiao Wang,
At Stability's Edge: How to Adjust Hyperparameters to Preserve Minima Selection in Asynchronous Training of Neural Networks?
Niv Giladi, Mor Shpigel Nacson, Elad Hoffer, Daniel Soudry,
Online and stochastic optimization beyond Lipschitz continuity: A Riemannian approach
Kimon Antonakopoulos, E. Veronica Belmega, Panayotis Mertikopoulos,


Why Gradient Clipping Accelerates Training: A Theoretical Justification for Adaptivity
Jingzhao Zhang, Tianxing He, Suvrit Sra, Ali Jadbabaie,
On the Convergence of FedAvg on Non-IID Data
Xiang Li, Kaixuan Huang, Wenhao Yang, Shusen Wang, Zhihua Zhang,
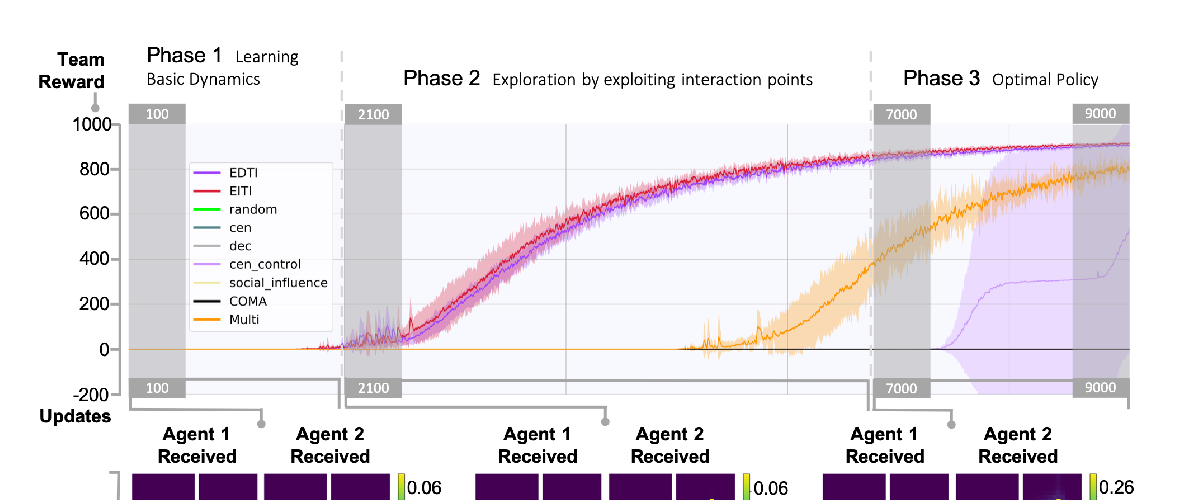
Emergent Tool Use From Multi-Agent Autocurricula
Bowen Baker, Ingmar Kanitscheider, Todor Markov, Yi Wu, Glenn Powell, Bob McGrew, Igor Mordatch,

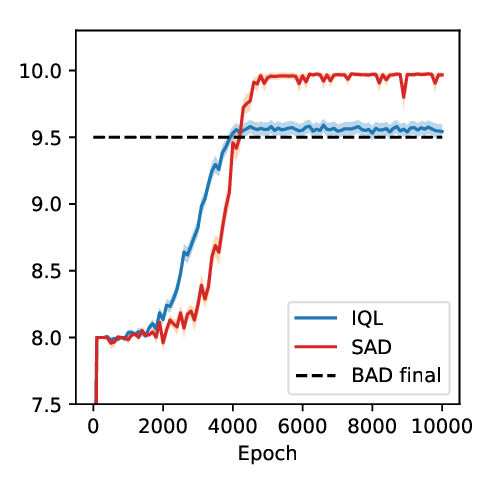
Simplified Action Decoder for Deep Multi-Agent Reinforcement Learning
Hengyuan Hu, Jakob N Foerster,
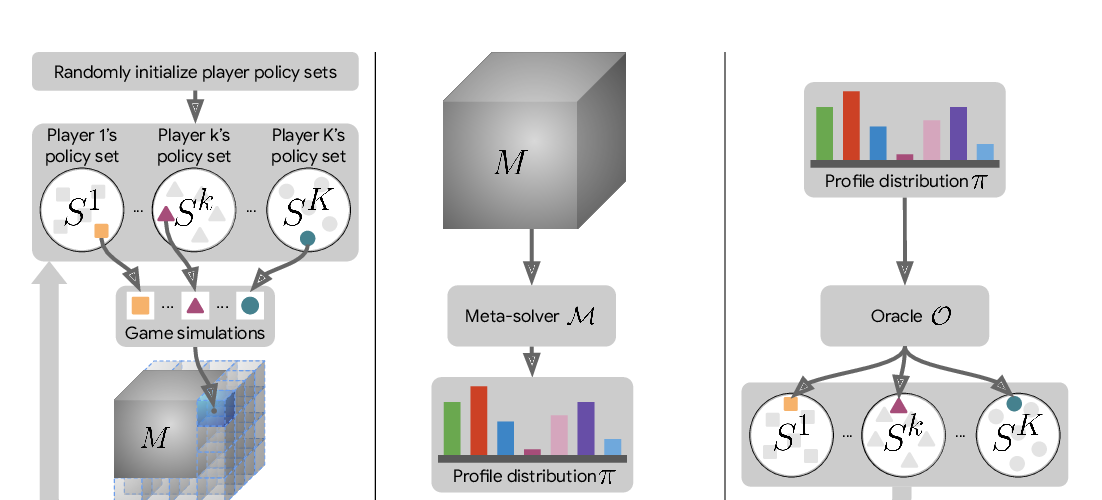
A Generalized Training Approach for Multiagent Learning
Paul Muller, Shayegan Omidshafiei, Mark Rowland, Karl Tuyls, Julien Perolat, Siqi Liu, Daniel Hennes, Luke Marris, Marc Lanctot, Edward Hughes, Zhe Wang, Guy Lever, Nicolas Heess, Thore Graepel, Remi Munos,
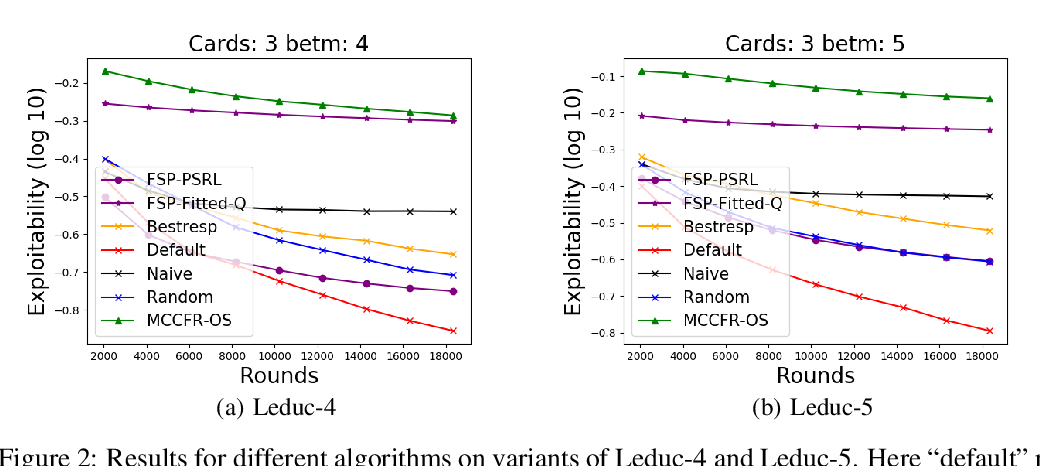
Posterior sampling for multi-agent reinforcement learning: solving extensive games with imperfect information
Yichi Zhou, Jialian Li, Jun Zhu,
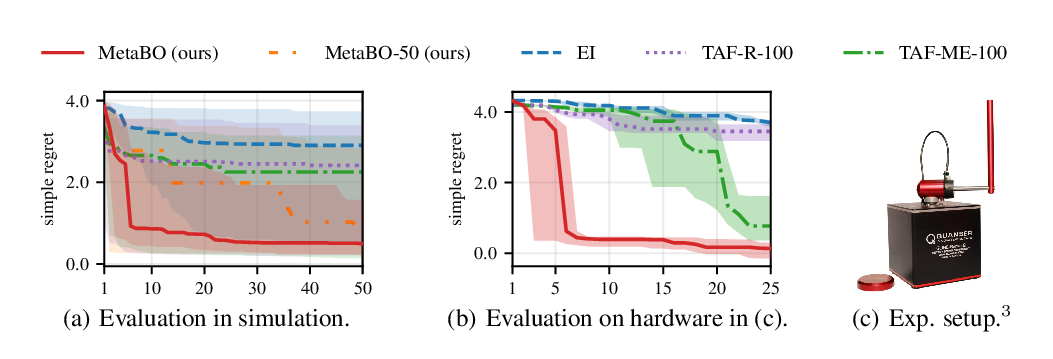
Meta-Learning Acquisition Functions for Transfer Learning in Bayesian Optimization
Michael Volpp, Lukas P. Fröhlich, Kirsten Fischer, Andreas Doerr, Stefan Falkner, Frank Hutter, Christian Daniel,
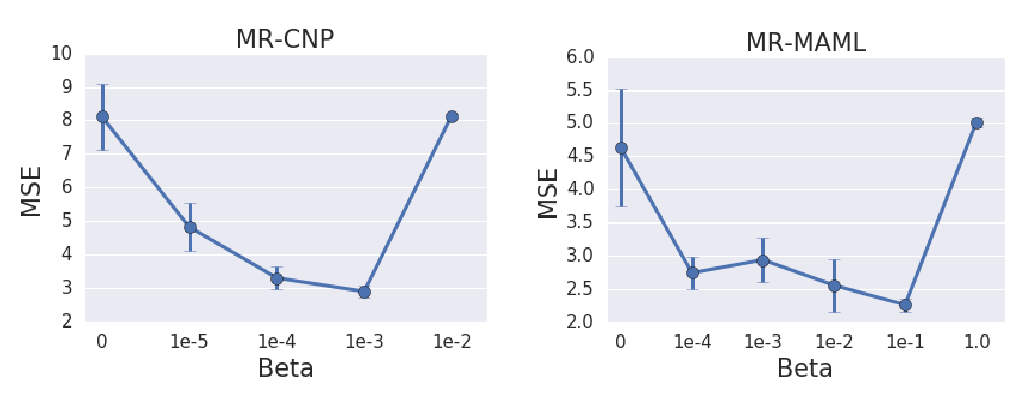
Meta-Learning without Memorization
Mingzhang Yin, George Tucker, Mingyuan Zhou, Sergey Levine, Chelsea Finn,
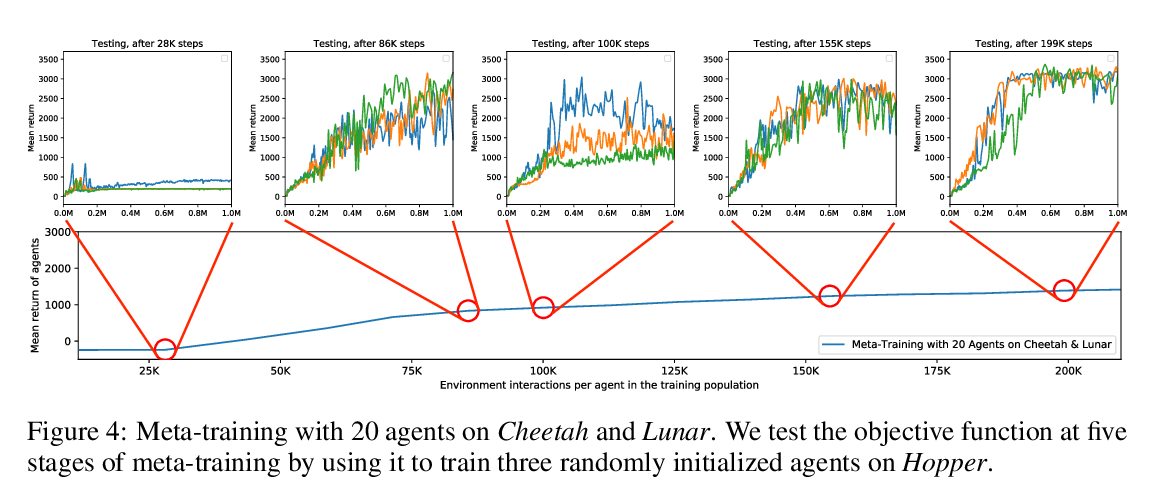
Improving Generalization in Meta Reinforcement Learning using Learned Objectives
Louis Kirsch, Sjoerd van Steenkiste, Juergen Schmidhuber,
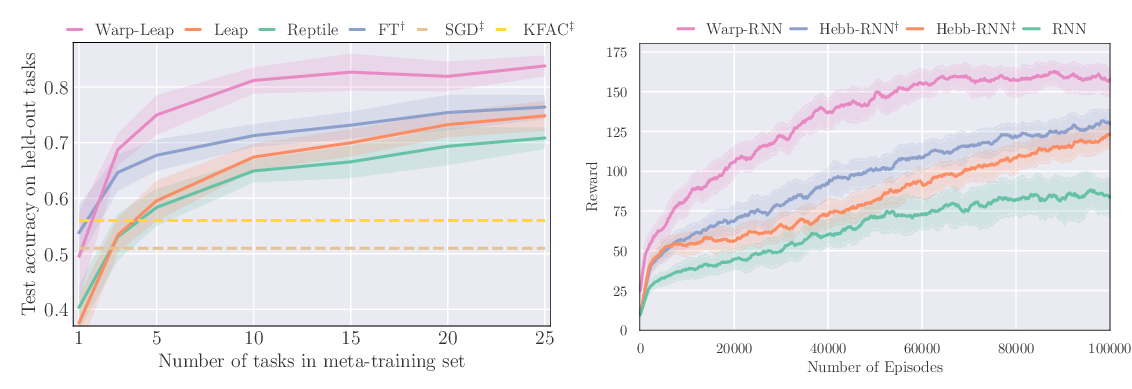
Meta-Learning with Warped Gradient Descent
Sebastian Flennerhag, Andrei A. Rusu, Razvan Pascanu, Francesco Visin, Hujun Yin, Raia Hadsell,
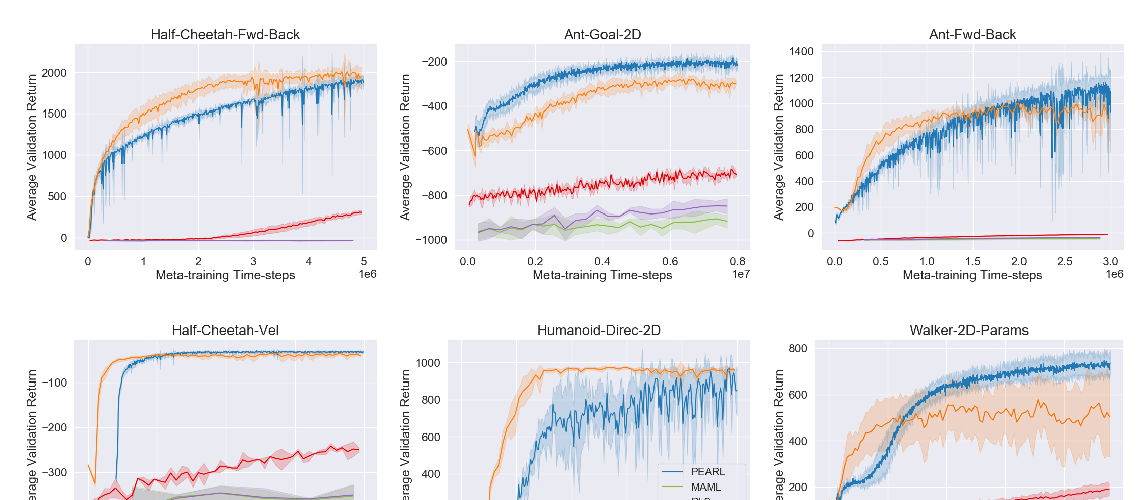
Hamiltonian Generative Networks
Peter Toth, Danilo J. Rezende, Andrew Jaegle, Sébastien Racanière, Aleksandar Botev, Irina Higgins,
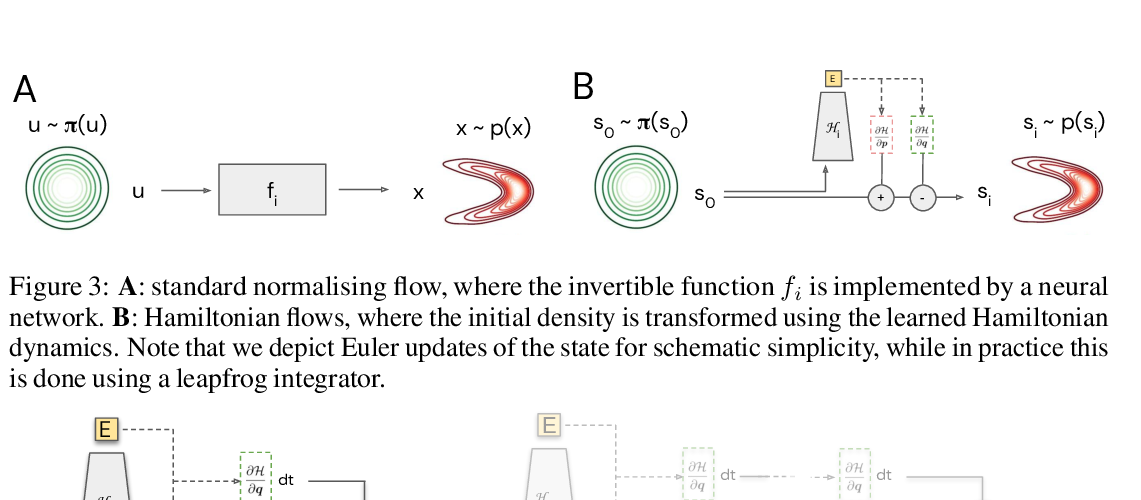
Stable Rank Normalization for Improved Generalization in Neural Networks and GANs
Amartya Sanyal, Philip H. Torr, Puneet K. Dokania,
Real or Not Real, that is the Question
Yuanbo Xiangli, Yubin Deng, Bo Dai, Chen Change Loy, Dahua Lin,

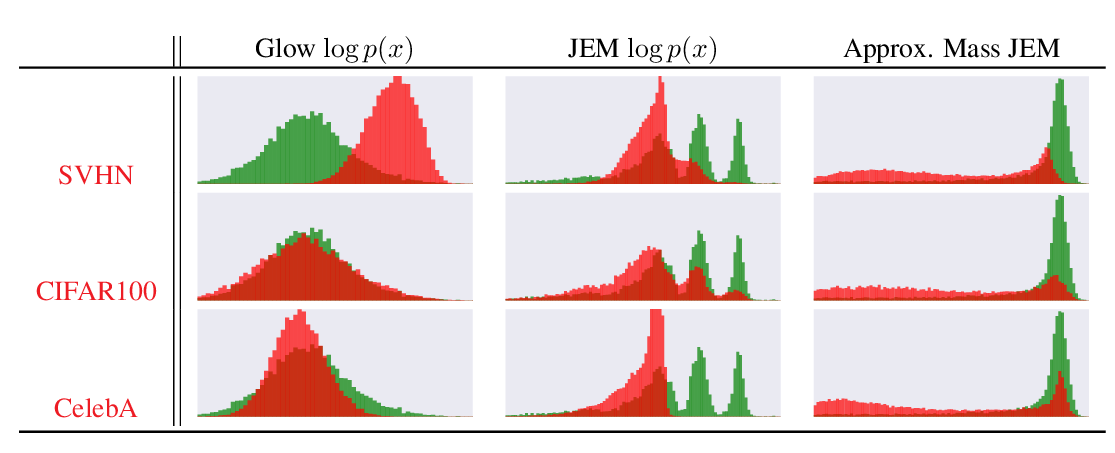
Your classifier is secretly an energy based model and you should treat it like one
Will Grathwohl, Kuan-Chieh Wang, Joern-Henrik Jacobsen, David Duvenaud, Mohammad Norouzi, Kevin Swersky,
Optimal Strategies Against Generative Attacks
Roy Mor, Erez Peterfreund, Matan Gavish, Amir Globerson,

How much Position Information Do Convolutional Neural Networks Encode?
Md Amirul Islam, Sen Jia, Neil D. B. Bruce,


High Fidelity Speech Synthesis with Adversarial Networks
Mikołaj Bińkowski, Jeff Donahue, Sander Dieleman, Aidan Clark, Erich Elsen, Norman Casagrande, Luis C. Cobo, Karen Simonyan,
Learning Hierarchical Discrete Linguistic Units from Visually-Grounded Speech
David Harwath, Wei-Ning Hsu, James Glass,
DDSP: Differentiable Digital Signal Processing
Jesse Engel, Lamtharn (Hanoi) Hantrakul, Chenjie Gu, Adam Roberts,
word2ket: Space-efficient Word Embeddings inspired by Quantum Entanglement
Aliakbar Panahi, Seyran Saeedi, Tom Arodz,
Tuesday


A Probabilistic Formulation of Unsupervised Text Style Transfer
Junxian He, Xinyi Wang, Graham Neubig, Taylor Berg-Kirkpatrick,
Unbiased Contrastive Divergence Algorithm for Training Energy-Based Latent Variable Models
Yixuan Qiu, Lingsong Zhang, Xiao Wang,
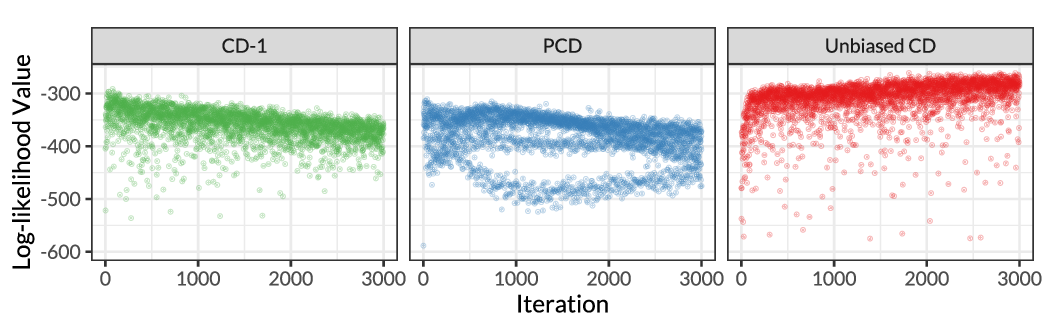
SUMO: Unbiased Estimation of Log Marginal Probability for Latent Variable Models
Yucen Luo, Alex Beatson, Mohammad Norouzi, Jun Zhu, David Duvenaud, Ryan P. Adams, Ricky T. Q. Chen,
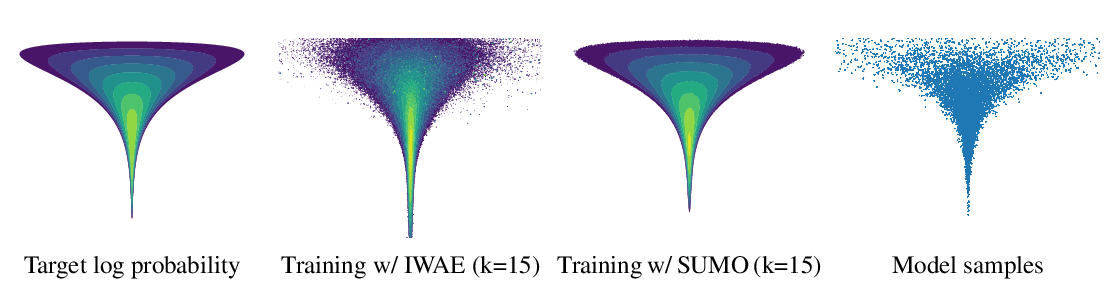

Intensity-Free Learning of Temporal Point Processes
Oleksandr Shchur, Marin Biloš, Stephan Günnemann,
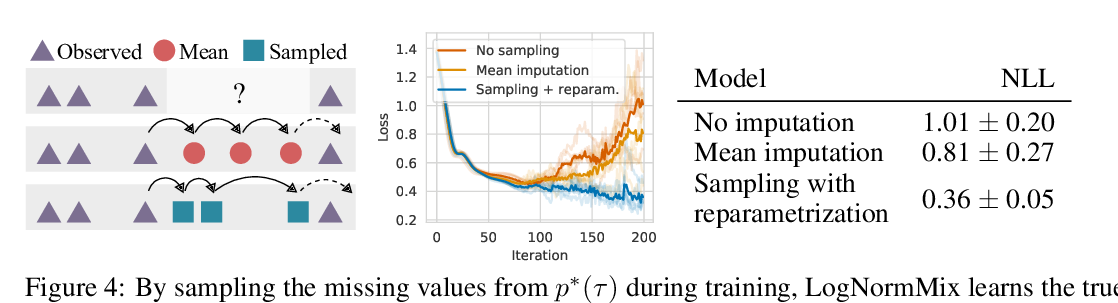
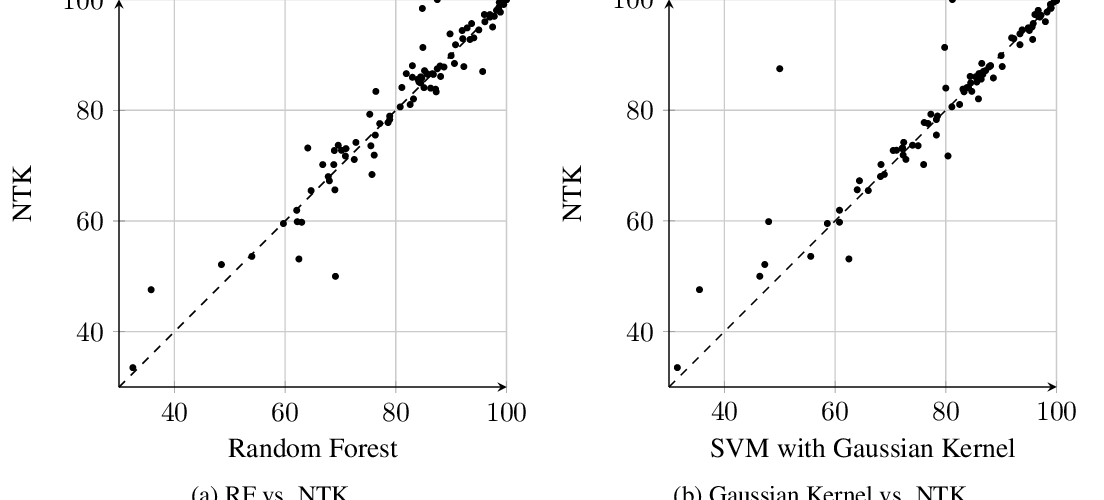
Neural Tangents: Fast and Easy Infinite Neural Networks in Python
Roman Novak, Lechao Xiao, Jiri Hron, Jaehoon Lee, Alexander A. Alemi, Jascha Sohl-Dickstein, Samuel S. Schoenholz,
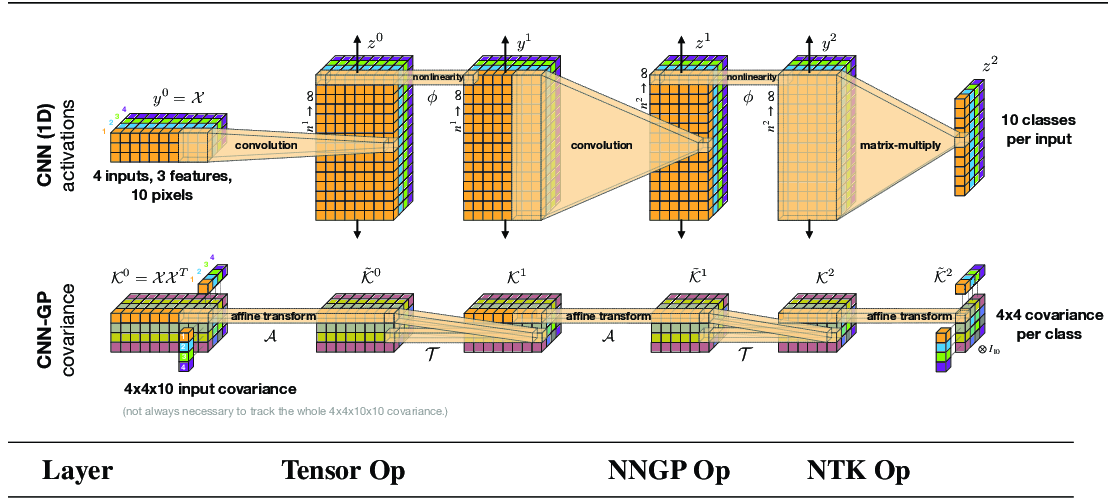
Learning to Balance: Bayesian Meta-Learning for Imbalanced and Out-of-distribution Tasks
Hae Beom Lee, Hayeon Lee, Donghyun Na, Saehoon Kim, Minseop Park, Eunho Yang, Sung Ju Hwang,
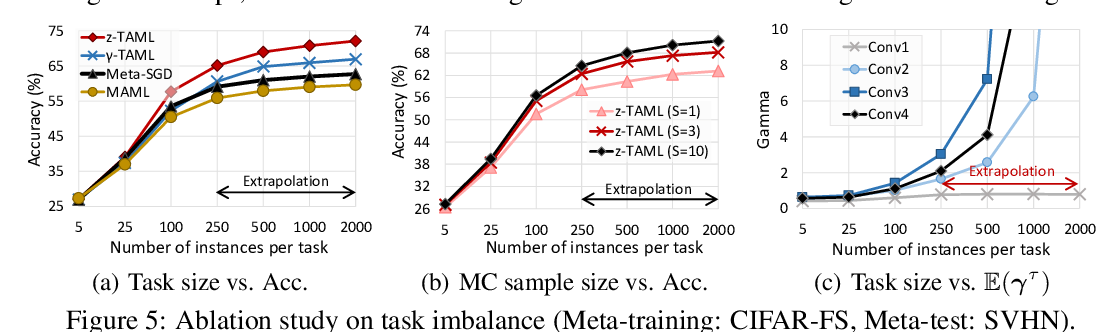
Cyclical Stochastic Gradient MCMC for Bayesian Deep Learning
Ruqi Zhang, Chunyuan Li, Jianyi Zhang, Changyou Chen, Andrew Gordon Wilson,
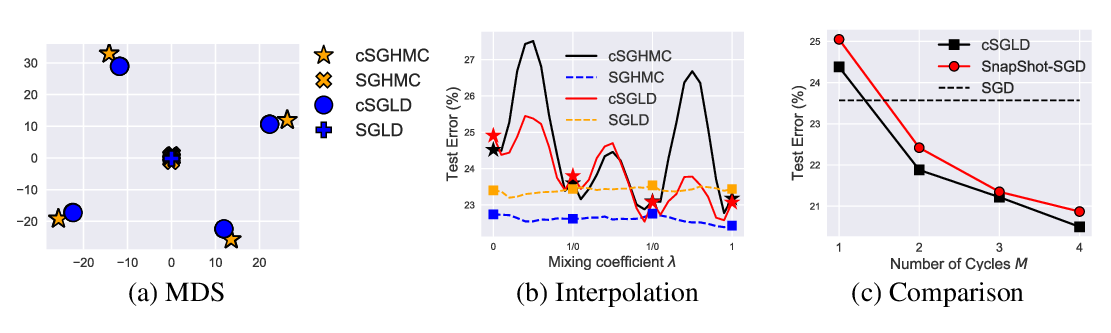
Emergence of functional and structural properties of the head direction system by optimization of recurrent neural networks
Christopher J. Cueva, Peter Y. Wang, Matthew Chin, Xue-Xin Wei,
Disentangling neural mechanisms for perceptual grouping
Junkyung Kim, Drew Linsley, Kalpit Thakkar, Thomas Serre,
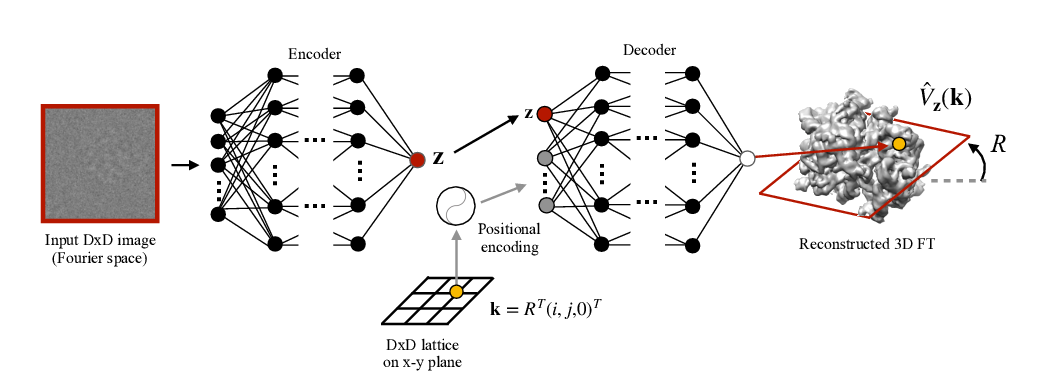
Reconstructing continuous distributions of 3D protein structure from cryo-EM images
Ellen D. Zhong, Tristan Bepler, Joseph H. Davis, Bonnie Berger,
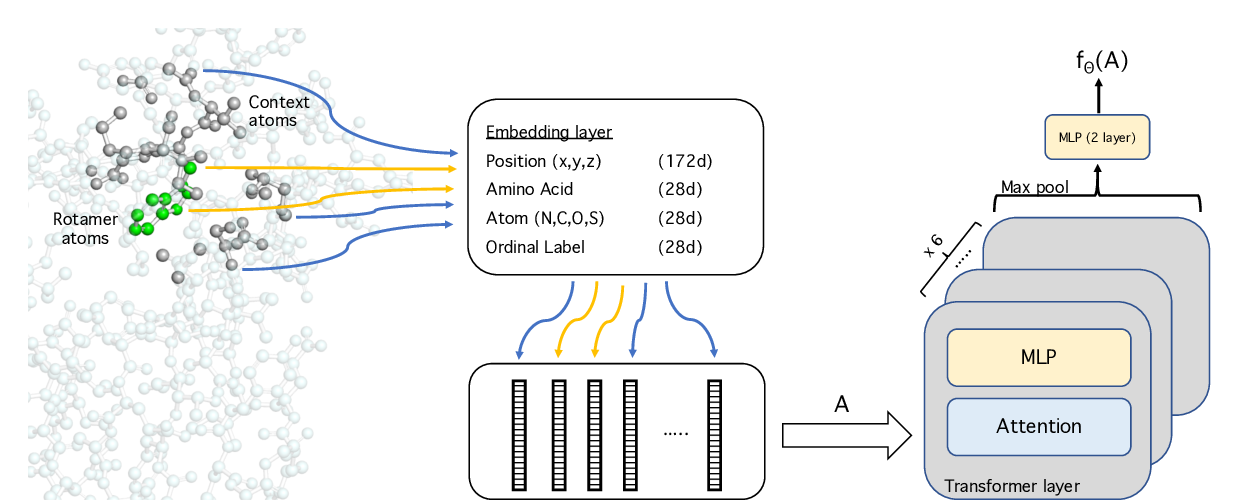
Energy-based models for atomic-resolution protein conformations
Yilun Du, Joshua Meier, Jerry Ma, Rob Fergus, Alexander Rives,
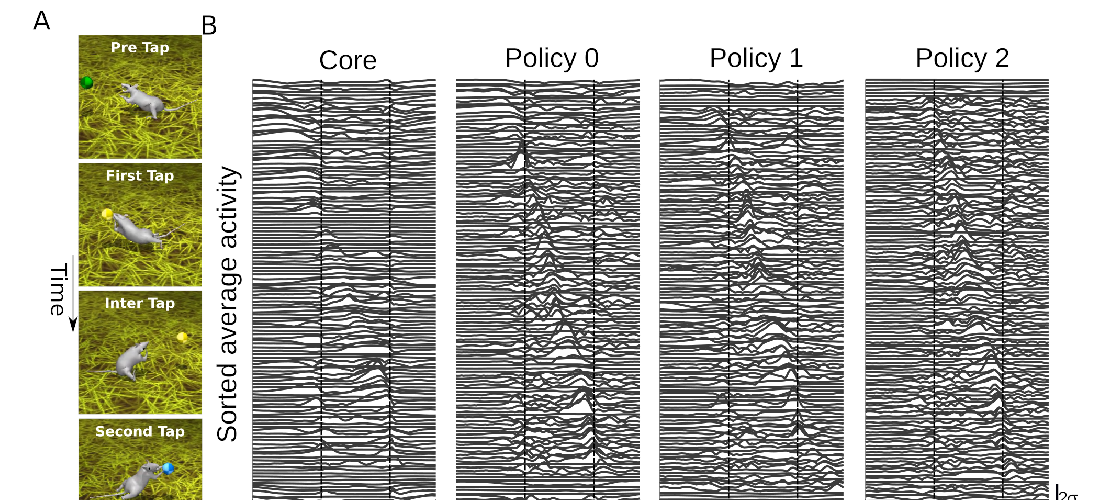
Deep neuroethology of a virtual rodent
Josh Merel, Diego Aldarondo, Jesse Marshall, Yuval Tassa, Greg Wayne, Bence Olveczky,
Rotation-invariant clustering of neuronal responses in primary visual cortex
Ivan Ustyuzhaninov, Santiago A. Cadena, Emmanouil Froudarakis, Paul G. Fahey, Edgar Y. Walker, Erick Cobos, Jacob Reimer, Fabian H. Sinz, Andreas S. Tolias, Matthias Bethge, Alexander S. Ecker,
RNA Secondary Structure Prediction By Learning Unrolled Algorithms
Xinshi Chen, Yu Li, Ramzan Umarov, Xin Gao, Le Song,
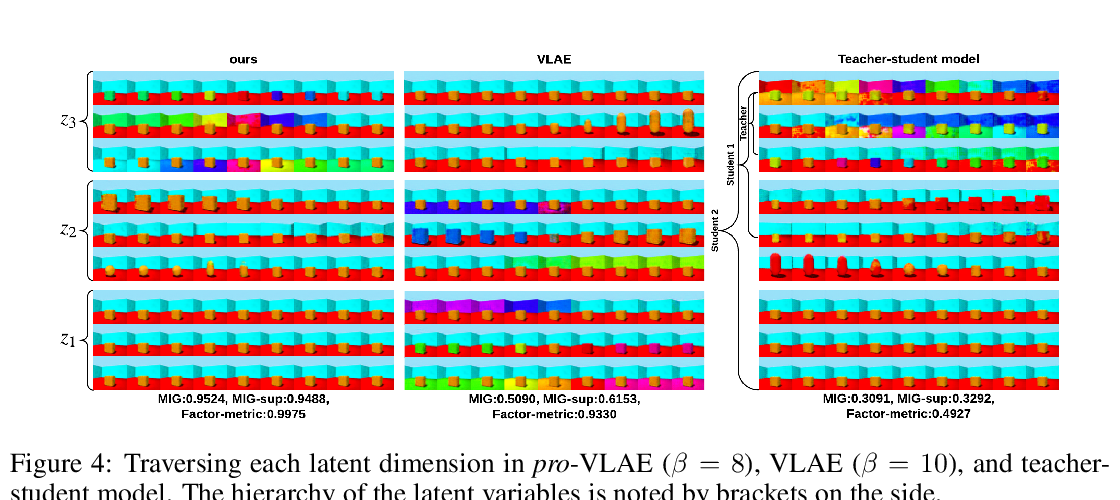
PROGRESSIVE LEARNING AND DISENTANGLEMENT OF HIERARCHICAL REPRESENTATIONS
Zhiyuan Li, Jaideep Vitthal Murkute, Prashnna Kumar Gyawali, Linwei Wang,
Disentanglement by Nonlinear ICA with General Incompressible-flow Networks (GIN)
Peter Sorrenson, Carsten Rother, Ullrich Köthe,
Kaleidoscope: An Efficient, Learnable Representation For All Structured Linear Maps
Tri Dao, Nimit Sohoni, Albert Gu, Matthew Eichhorn, Amit Blonder, Megan Leszczynski, Atri Rudra, Christopher Ré,

Harnessing the Power of Infinitely Wide Deep Nets on Small-data Tasks
Sanjeev Arora, Simon S. Du, Zhiyuan Li, Ruslan Salakhutdinov, Ruosong Wang, Dingli Yu,
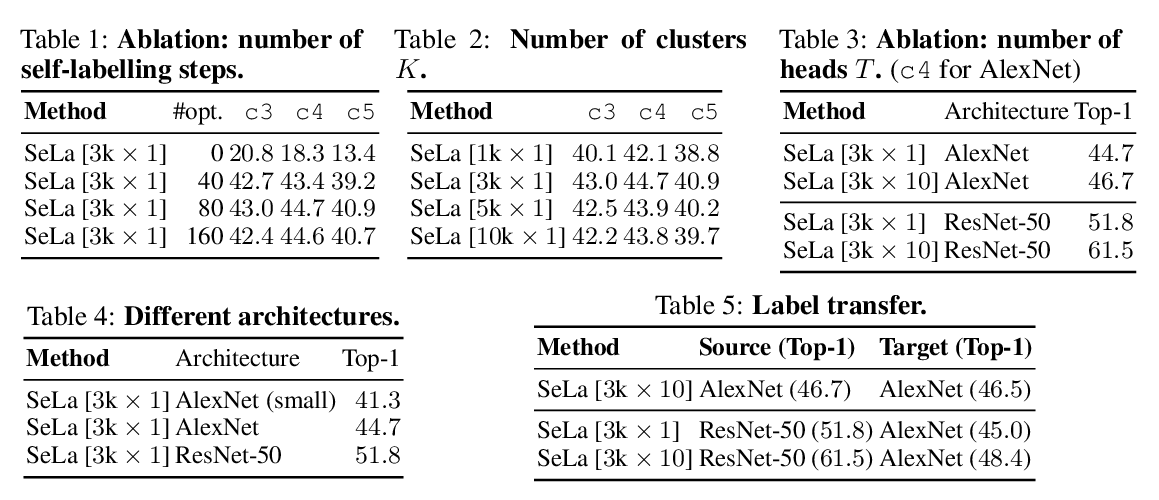
Self-labelling via simultaneous clustering and representation learning
Asano YM., Rupprecht C., Vedaldi A.,
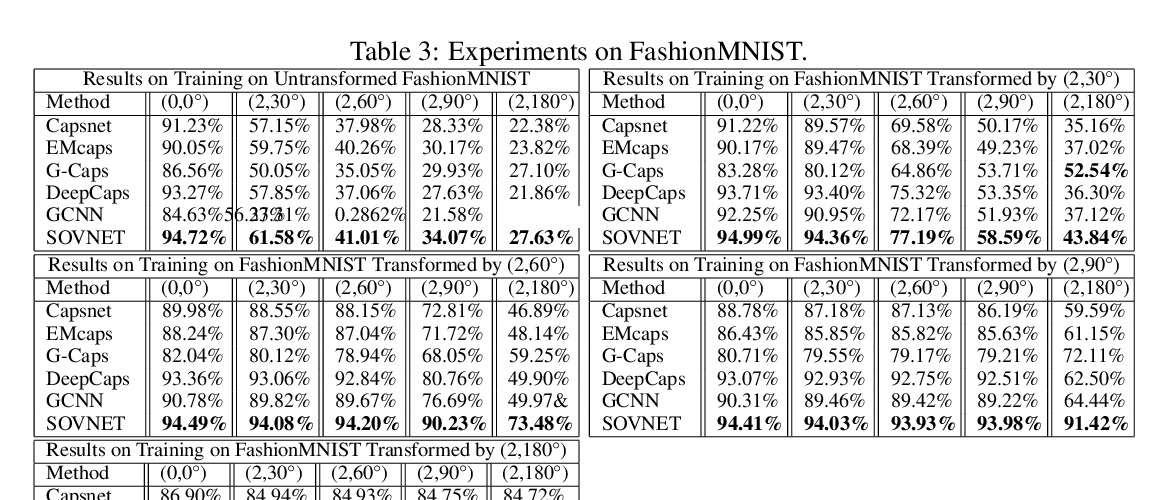
Building Deep Equivariant Capsule Networks
Sai Raam Venkataraman, S. Balasubramanian, R. Raghunatha Sarma,
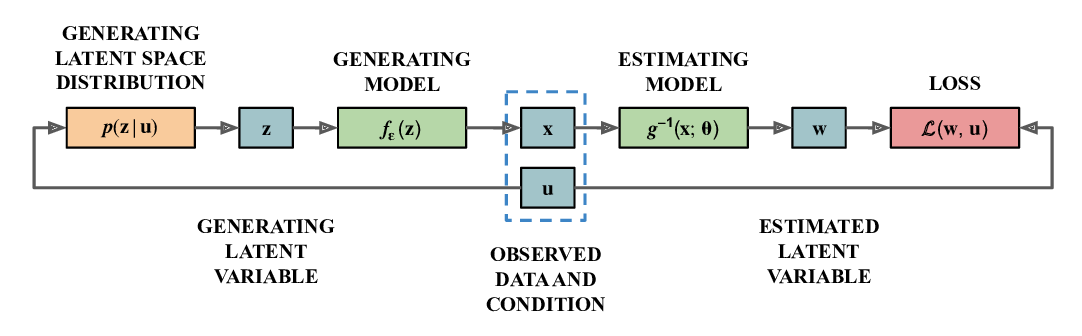
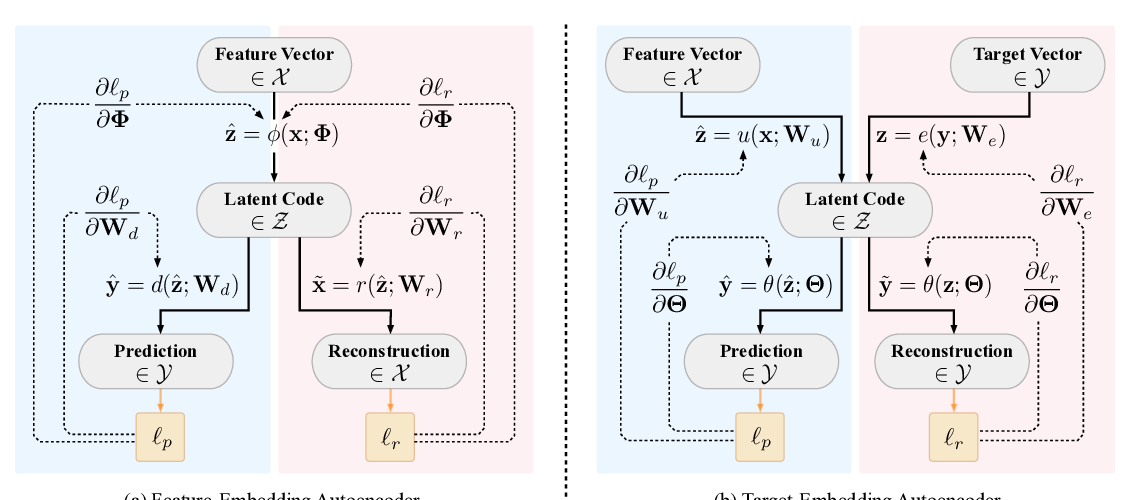
Target-Embedding Autoencoders for Supervised Representation Learning
Daniel Jarrett, Mihaela van der Schaar,
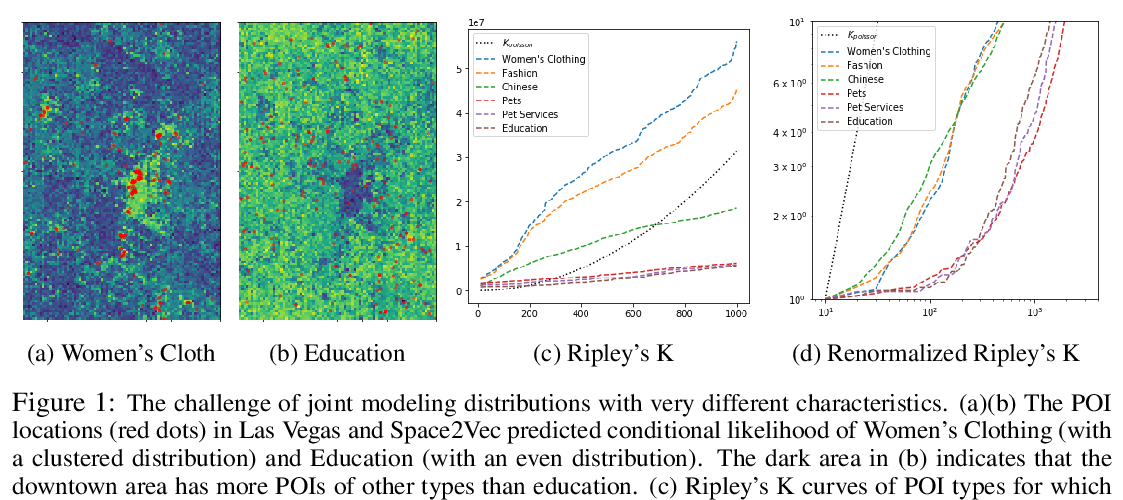
Multi-Scale Representation Learning for Spatial Feature Distributions using Grid Cells
Gengchen Mai, Krzysztof Janowicz, Bo Yan, Rui Zhu, Ling Cai, Ni Lao,
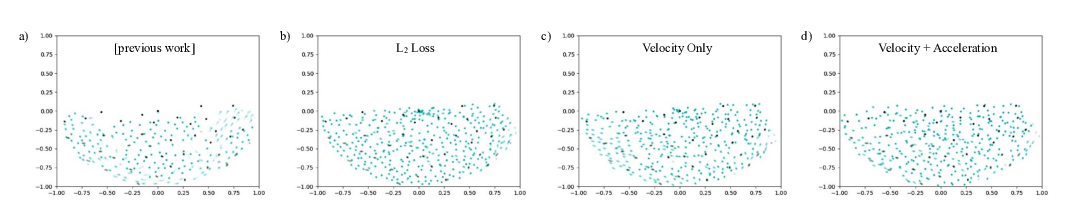
Tranquil Clouds: Neural Networks for Learning Temporally Coherent Features in Point Clouds
Lukas Prantl, Nuttapong Chentanez, Stefan Jeschke, Nils Thuerey,
Convolutional Conditional Neural Processes
Jonathan Gordon, Wessel P. Bruinsma, Andrew Y. K. Foong, James Requeima, Yann Dubois, Richard E. Turner,
Restricting the Flow: Information Bottlenecks for Attribution
Karl Schulz, Leon Sixt, Federico Tombari, Tim Landgraf,

Estimating Gradients for Discrete Random Variables by Sampling without Replacement
Wouter Kool, Herke van Hoof, Max Welling,
Maximum Likelihood Constraint Inference for Inverse Reinforcement Learning
Dexter R.R. Scobee, S. Shankar Sastry,
Is a Good Representation Sufficient for Sample Efficient Reinforcement Learning?
Simon S. Du, Sham M. Kakade, Ruosong Wang, Lin F. Yang,
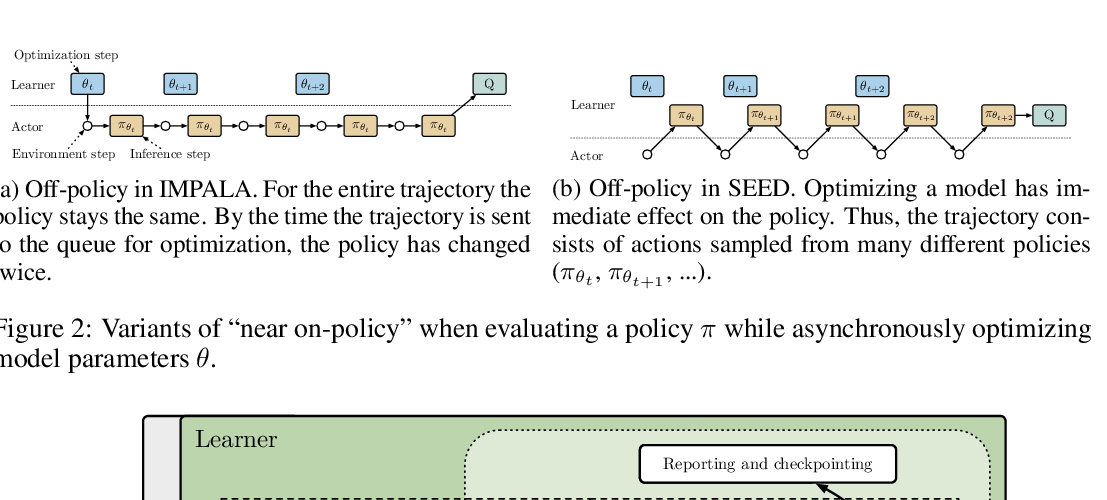
SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference
Lasse Espeholt, Raphaël Marinier, Piotr Stanczyk, Ke Wang, Marcin Michalski,
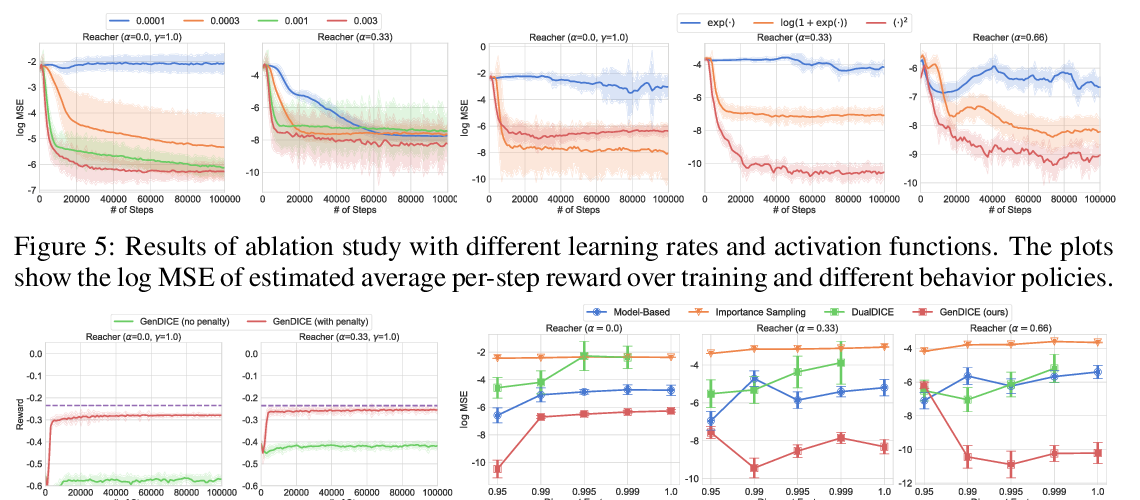
GenDICE: Generalized Offline Estimation of Stationary Values
Ruiyi Zhang, Bo Dai, Lihong Li, Dale Schuurmans,
Wednesday


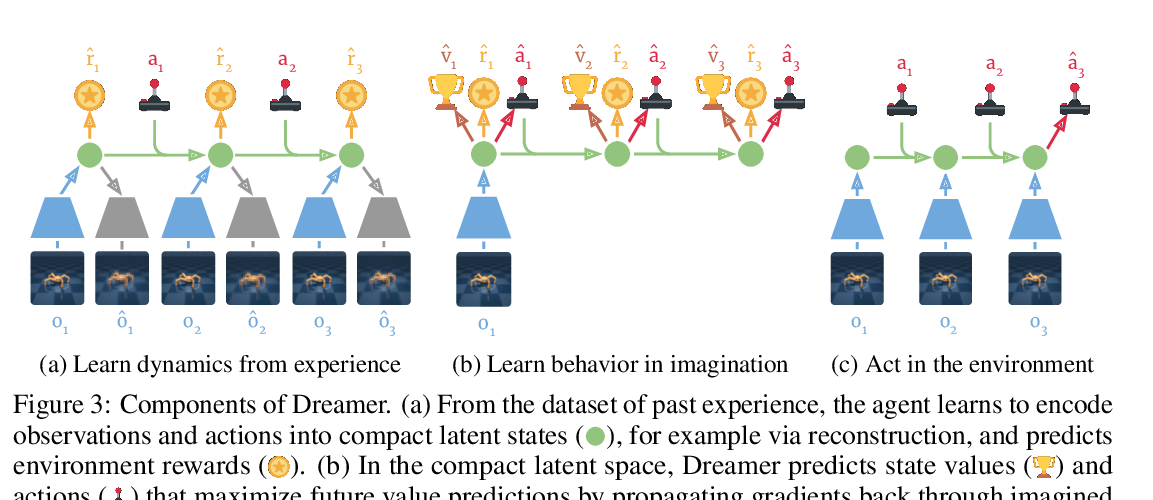
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, Mohammad Norouzi,
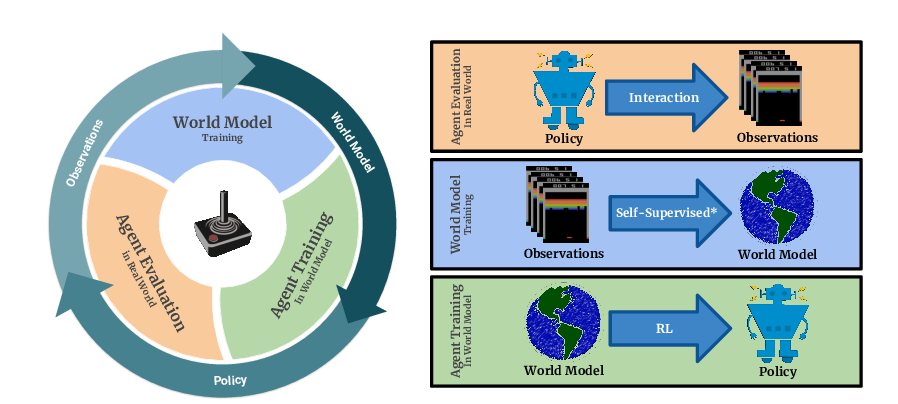
Model Based Reinforcement Learning for Atari
Łukasz Kaiser, Mohammad Babaeizadeh, Piotr Miłos, Błażej Osiński, Roy H Campbell, Konrad Czechowski, Dumitru Erhan, Chelsea Finn, Piotr Kozakowski, Sergey Levine, Afroz Mohiuddin, Ryan Sepassi, George Tucker, Henryk Michalewski,
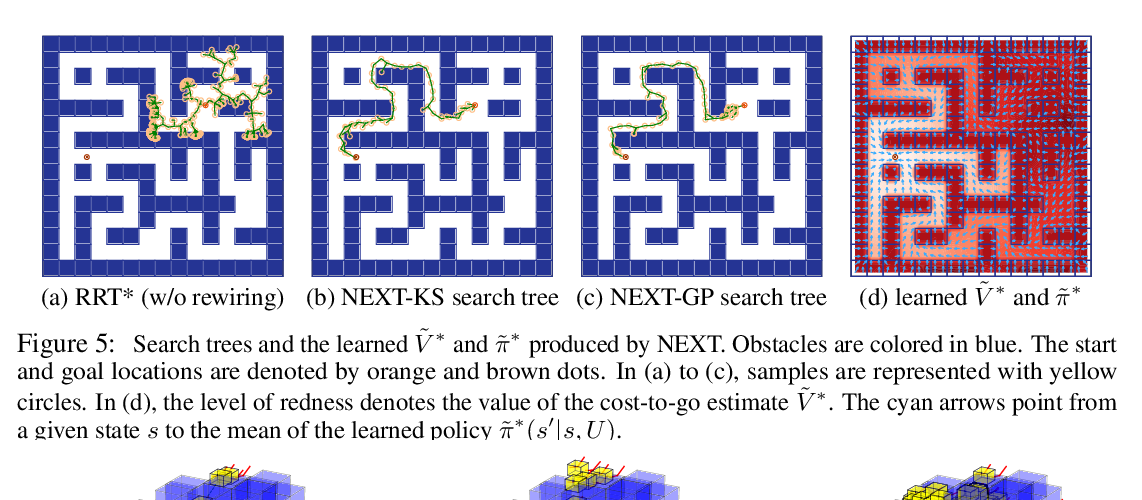
Learning to Plan in High Dimensions via Neural Exploration-Exploitation Trees
Binghong Chen, Bo Dai, Qinjie Lin, Guo Ye, Han Liu, Le Song,
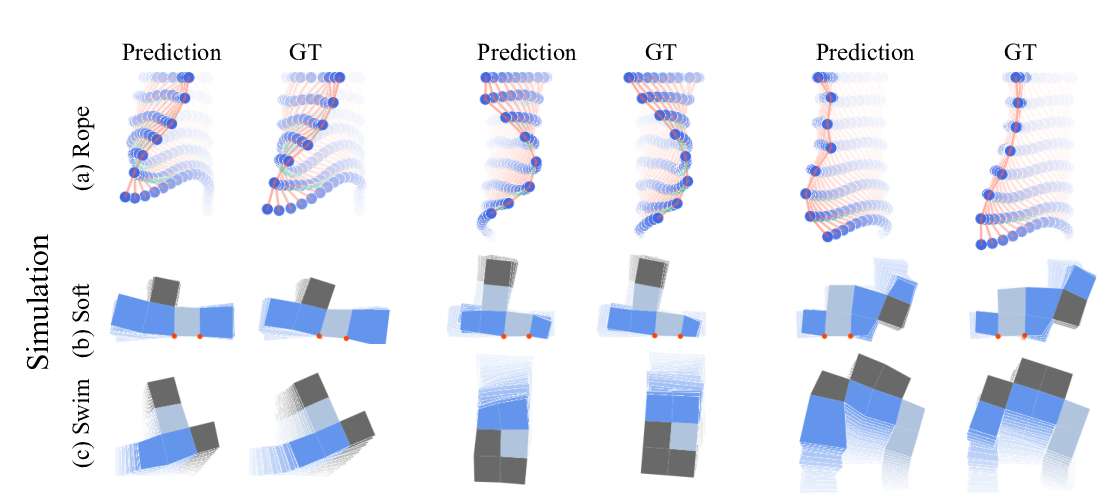
Learning Compositional Koopman Operators for Model-Based Control
Yunzhu Li, Hao He, Jiajun Wu, Dina Katabi, Antonio Torralba,
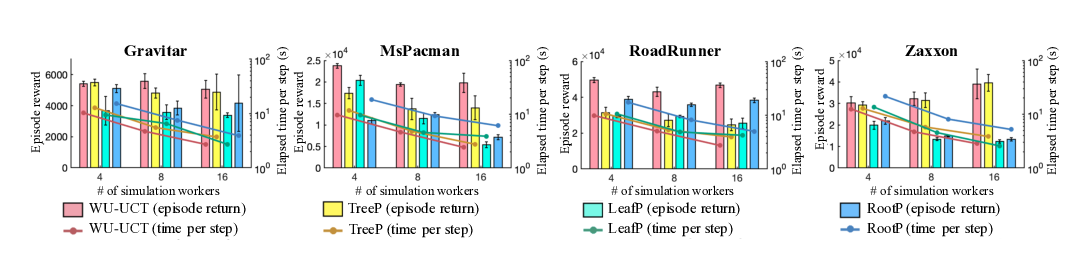
Watch the Unobserved: A Simple Approach to Parallelizing Monte Carlo Tree Search
Anji Liu, Jianshu Chen, Mingze Yu, Yu Zhai, Xuewen Zhou, Ji Liu,
Harnessing Structures for Value-Based Planning and Reinforcement Learning
Yuzhe Yang, Guo Zhang, Zhi Xu, Dina Katabi,
Compression based bound for non-compressed network: unified generalization error analysis of large compressible deep neural network
Taiji Suzuki, Hiroshi Abe, Tomoaki Nishimura,
Graph Neural Networks Exponentially Lose Expressive Power for Node Classification
Kenta Oono, Taiji Suzuki,
What Can Neural Networks Reason About?
Keyulu Xu, Jingling Li, Mozhi Zhang, Simon S. Du, Ken-ichi Kawarabayashi, Stefanie Jegelka,

The intriguing role of module criticality in the generalization of deep networks
Niladri Chatterji, Behnam Neyshabur, Hanie Sedghi,
Truth or backpropaganda? An empirical investigation of deep learning theory
Micah Goldblum, Jonas Geiping, Avi Schwarzschild, Michael Moeller, Tom Goldstein,
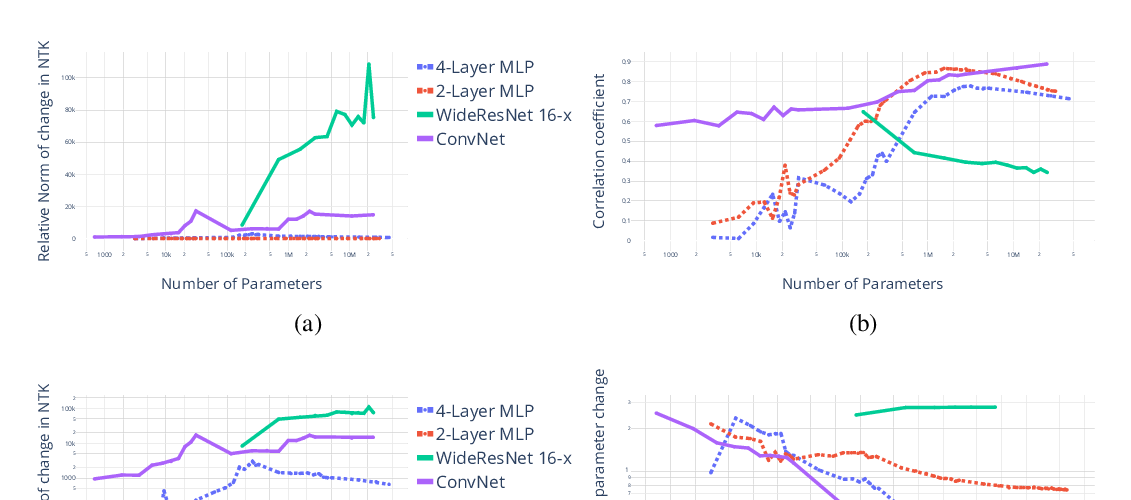
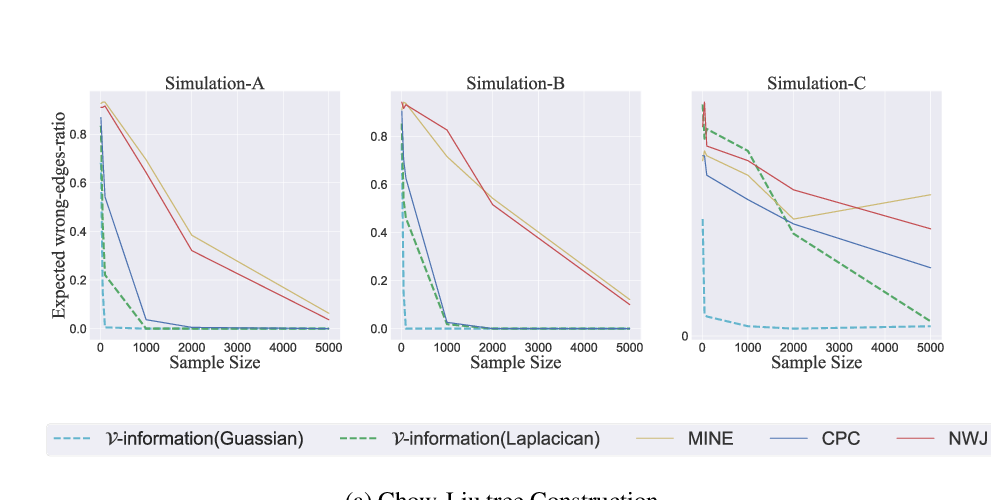
A Theory of Usable Information under Computational Constraints
Yilun Xu, Shengjia Zhao, Jiaming Song, Russell Stewart, Stefano Ermon,
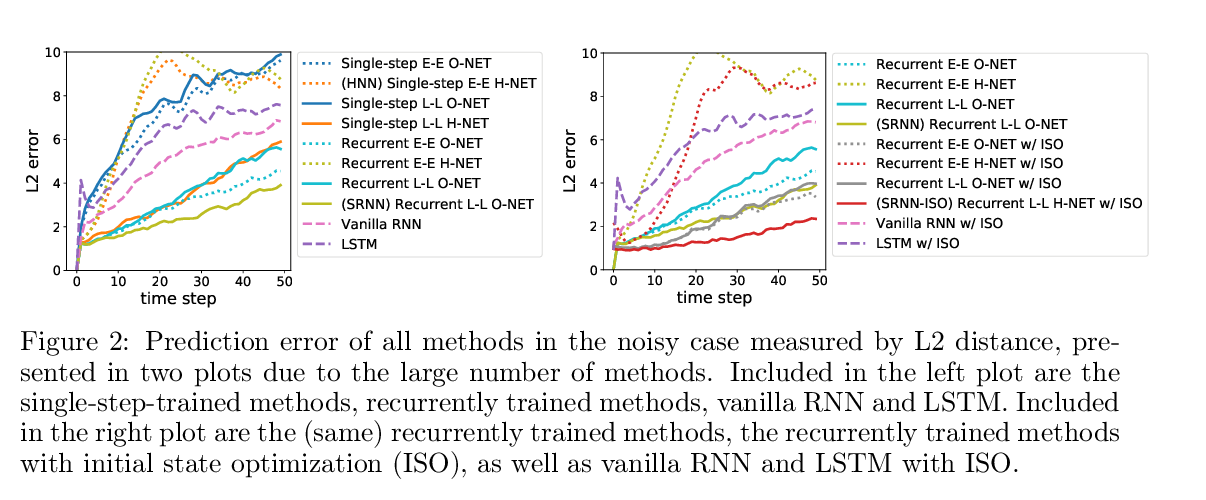
Encoding word order in complex embeddings
Benyou Wang, Donghao Zhao, Christina Lioma, Qiuchi Li, Peng Zhang, Jakob Grue Simonsen,
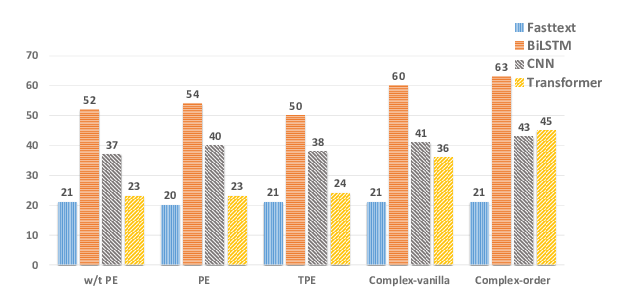
A Mutual Information Maximization Perspective of Language Representation Learning
Lingpeng Kong, Cyprien de Masson d'Autume, Lei Yu, Wang Ling, Zihang Dai, Dani Yogatama,
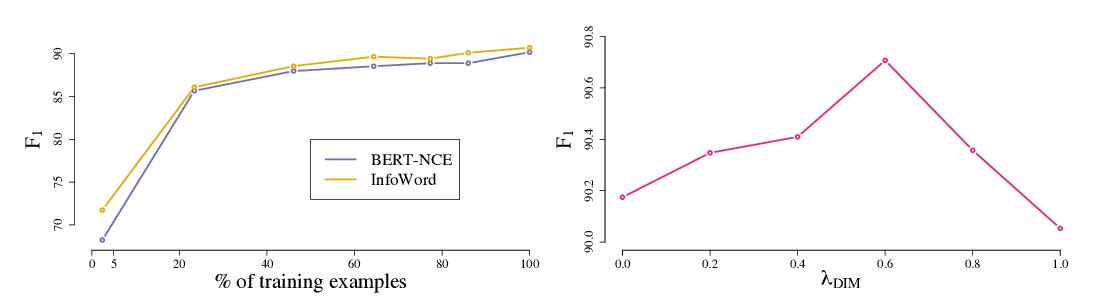
Duration-of-Stay Storage Assignment under Uncertainty
Michael Lingzhi Li, Elliott Wolf, Daniel Wintz,
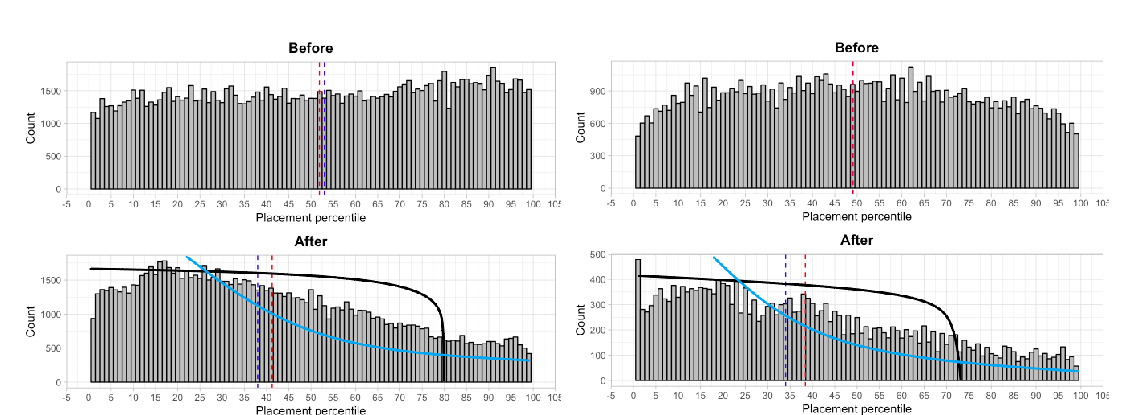
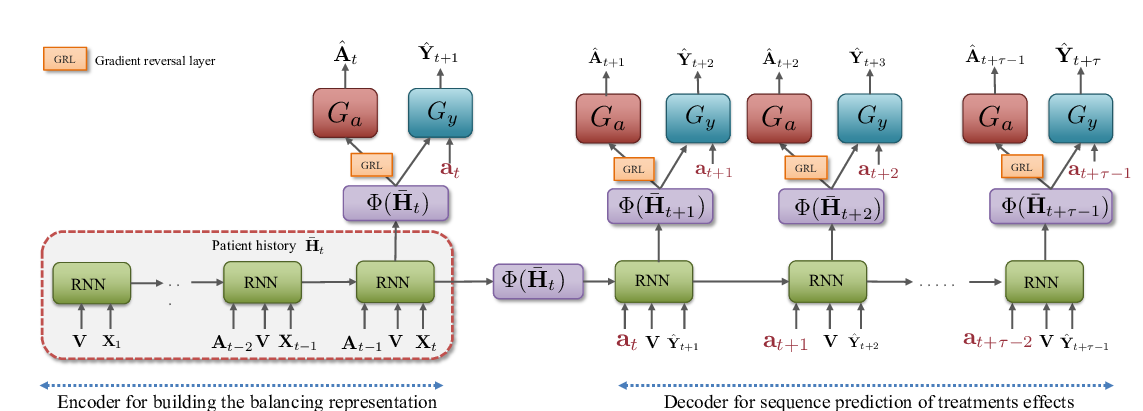
Estimating counterfactual treatment outcomes over time through adversarially balanced representations
Ioana Bica, Ahmed M Alaa, James Jordon, Mihaela van der Schaar,
CoPhy: Counterfactual Learning of Physical Dynamics
Fabien Baradel, Natalia Neverova, Julien Mille, Greg Mori, Christian Wolf,
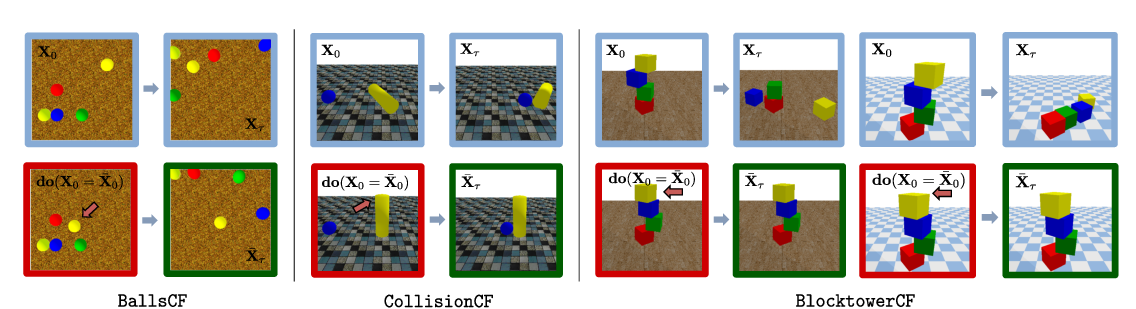
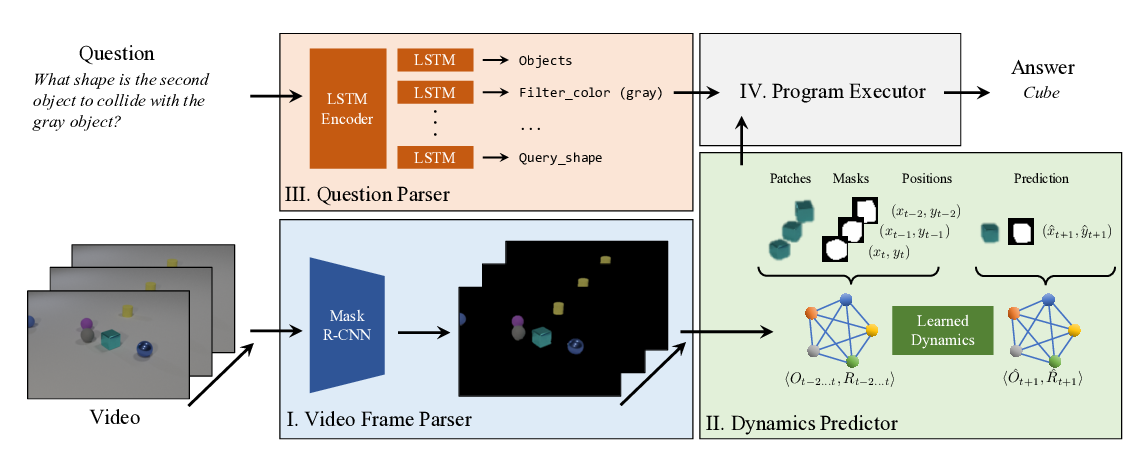
CLEVRER: Collision Events for Video Representation and Reasoning
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, Joshua B. Tenenbaum,
CATER: A diagnostic dataset for Compositional Actions & TEmporal Reasoning
Rohit Girdhar, Deva Ramanan,

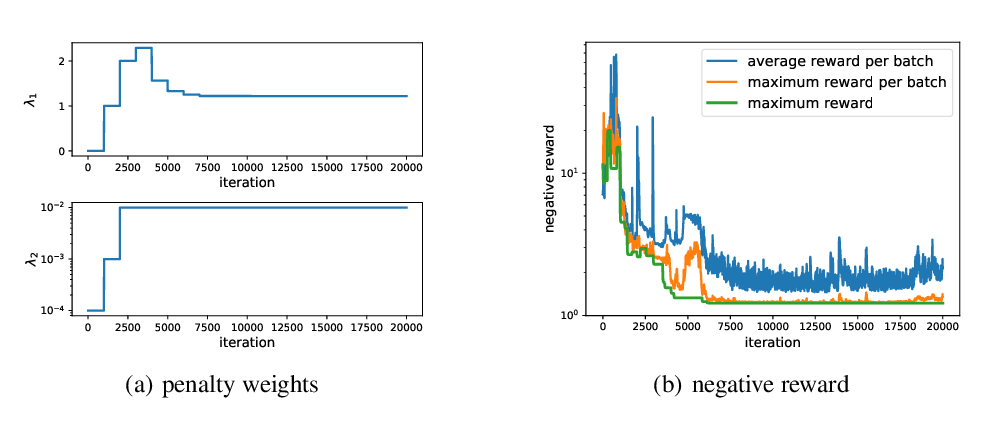
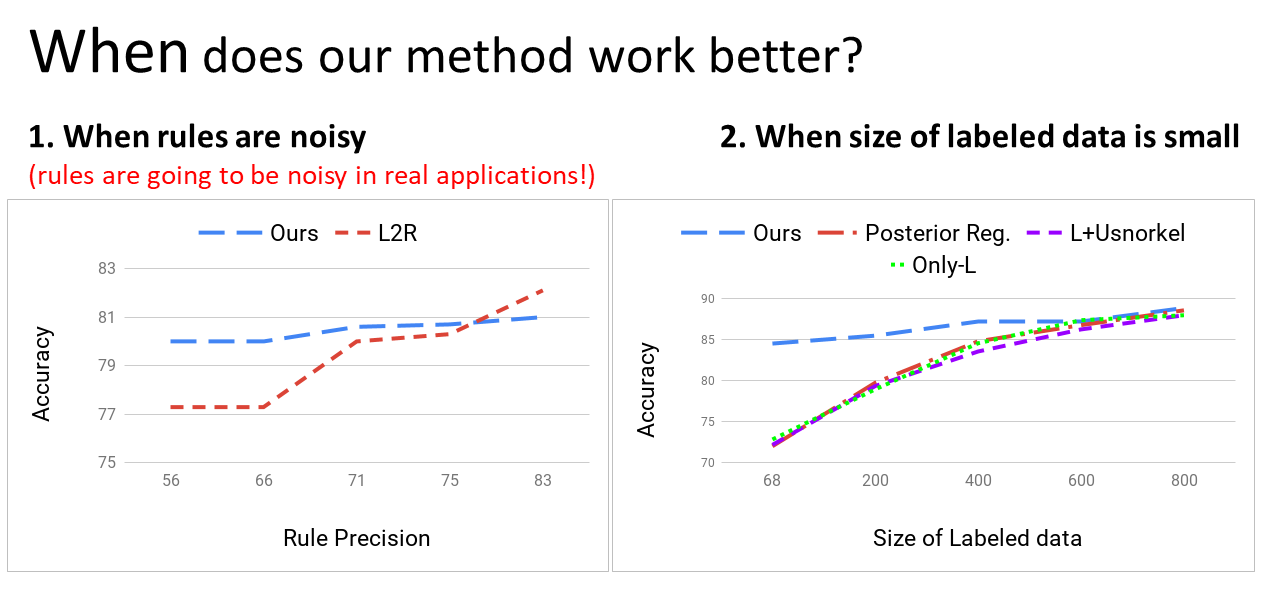
Learning from Rules Generalizing Labeled Exemplars
Abhijeet Awasthi, Sabyasachi Ghosh, Rasna Goyal, Sunita Sarawagi,
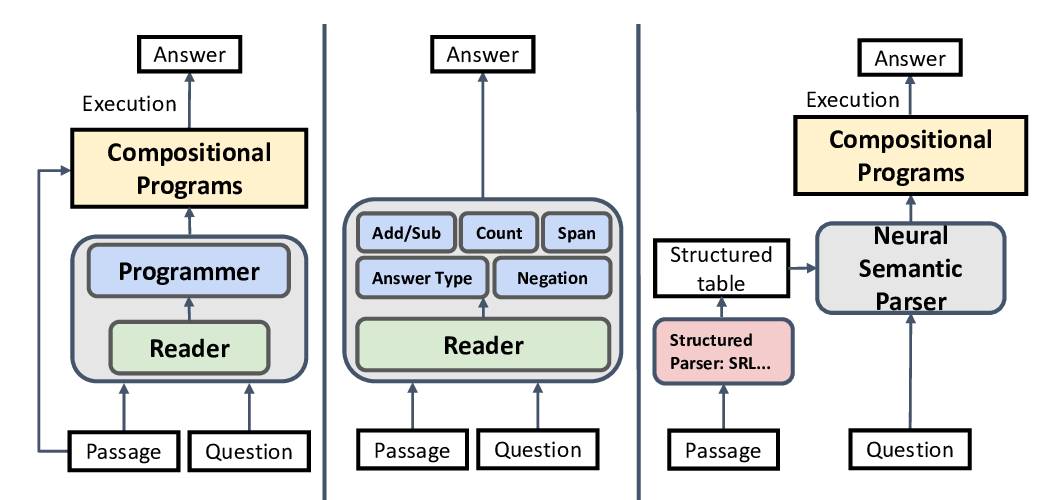
Neural Symbolic Reader: Scalable Integration of Distributed and Symbolic Representations for Reading Comprehension
Xinyun Chen, Chen Liang, Adams Wei Yu, Denny Zhou, Dawn Song, Quoc V. Le,
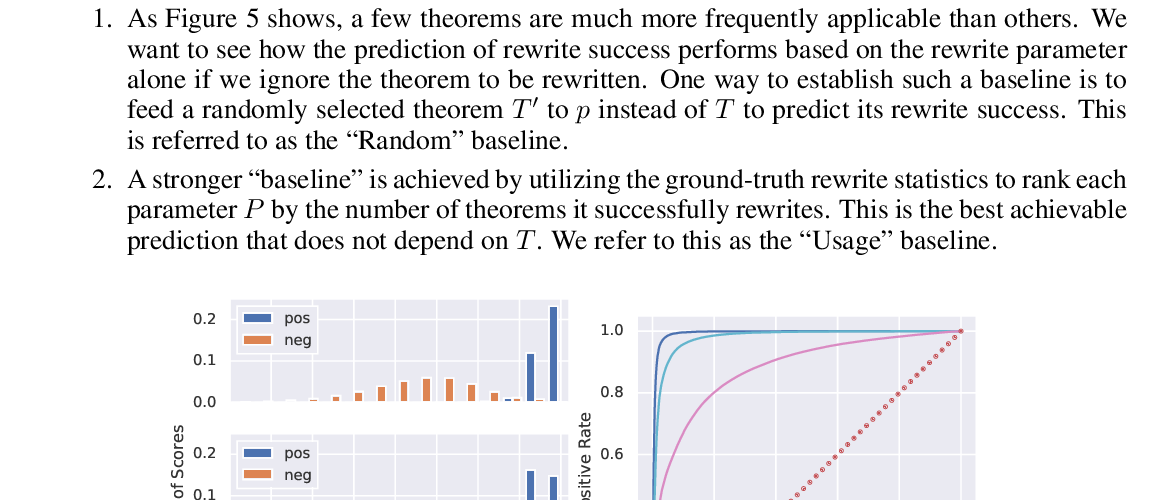
Mathematical Reasoning in Latent Space
Dennis Lee, Christian Szegedy, Markus Rabe, Sarah Loos, Kshitij Bansal,
Intrinsically Motivated Discovery of Diverse Patterns in Self-Organizing Systems
Chris Reinke, Mayalen Etcheverry, Pierre-Yves Oudeyer,

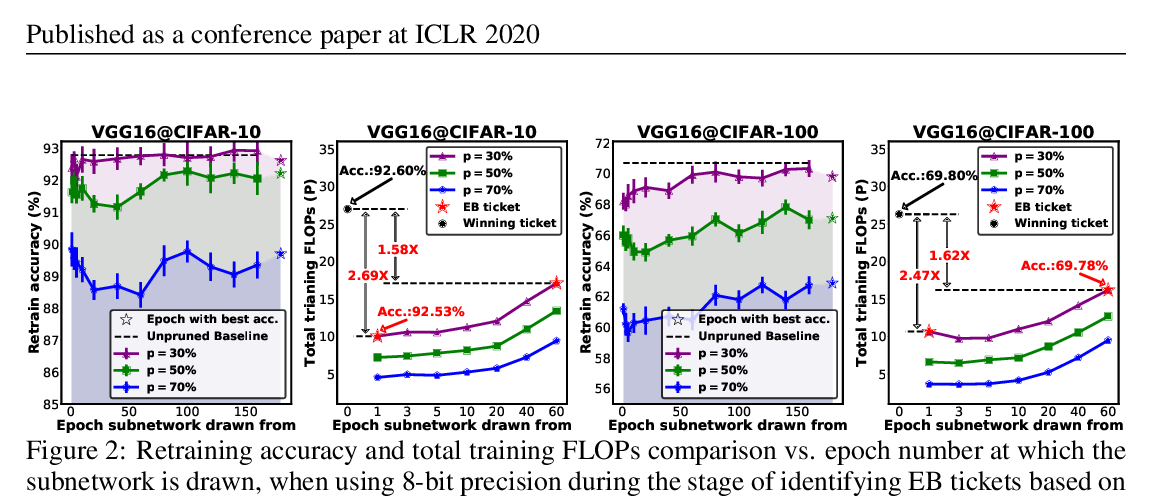
Drawing Early-Bird Tickets: Toward More Efficient Training of Deep Networks
Haoran You, Chaojian Li, Pengfei Xu, Yonggan Fu, Yue Wang, Xiaohan Chen, Richard G. Baraniuk, Zhangyang Wang, Yingyan Lin,
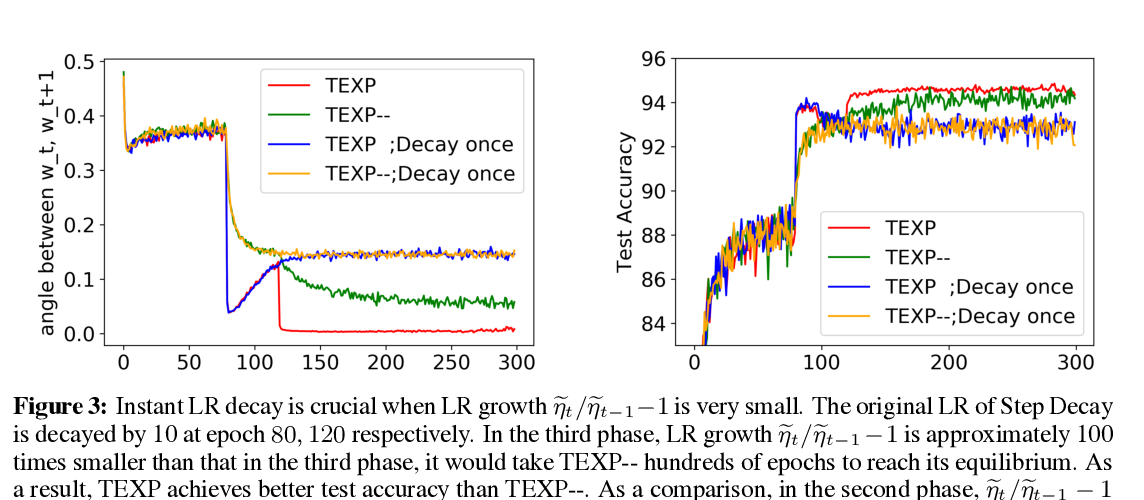
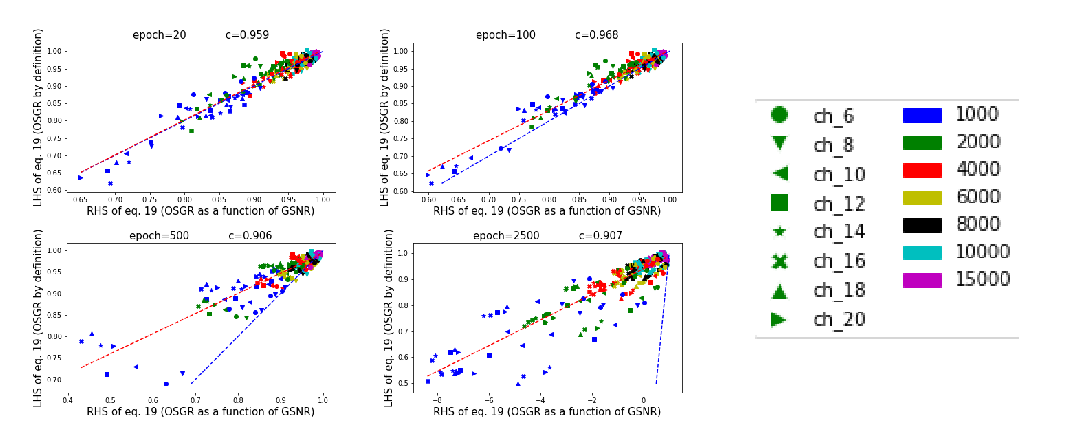
Understanding Why Neural Networks Generalize Well Through GSNR of Parameters
Jinlong Liu, Yunzhi Bai, Guoqing Jiang, Ting Chen, Huayan Wang,
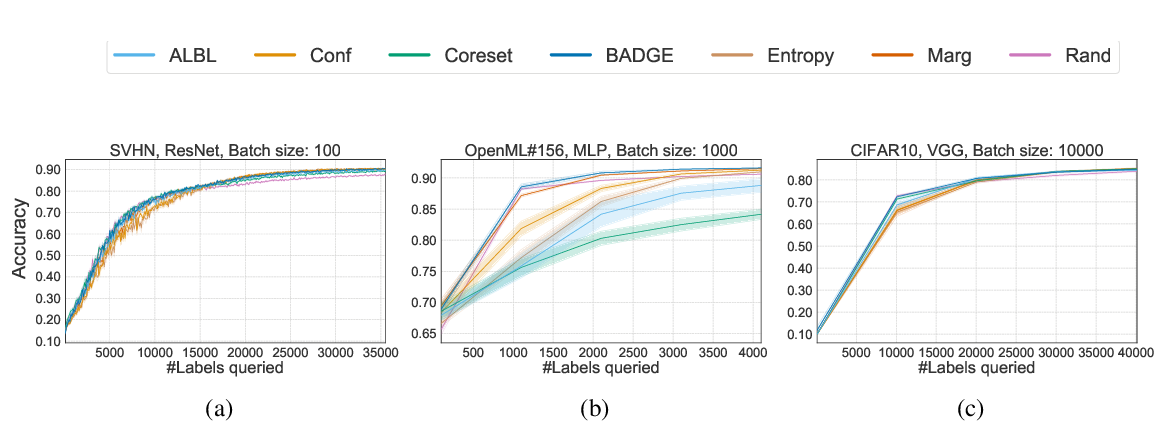
Deep Batch Active Learning by Diverse, Uncertain Gradient Lower Bounds
Jordan T. Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, Alekh Agarwal,
Geometric Analysis of Nonconvex Optimization Landscapes for Overcomplete Learning
Qing Qu, Yuexiang Zhai, Xiao Li, Yuqian Zhang, Zhihui Zhu,

Thursday

Yann LeCun (The Future is Self-Supervised): Humans and animals learn enormous amount of background knowledge about the world in the early months of life with little supervision and almost no interactions. How can we reproduce this learning paradigm in machines? One proposal for doing so is Self-Supervised Learning (SSL) in which a system is trained to predict a part of the input from the rest of the input. SSL, in the form of denoising auto-encoder, has been astonishingly successful for learning task-independent representations of text. But the success has not been translated to images and videos. The main obstacle is how to represent uncertainty in high-dimensional continuous spaces in which probability densities are generally intractable. We propose to use Energy-Based Models (EBM) to represent data manifolds or level-sets of distributions on the variables to be predicted. There are two classes of methods to train EBMs: (1) contrastive methods that push down on the energy of data points and push up elsewhere; (2) architectural and regularizing methods that limit or minimize the volume of space that can take low energies by regularizing the information capacity of a latent variable. While contrastive methods have been somewhat successful to learn image features, they are very expensive computationally. I will propose that the future of self-supervised representation learning lies in regularized latent-variable energy-based models.

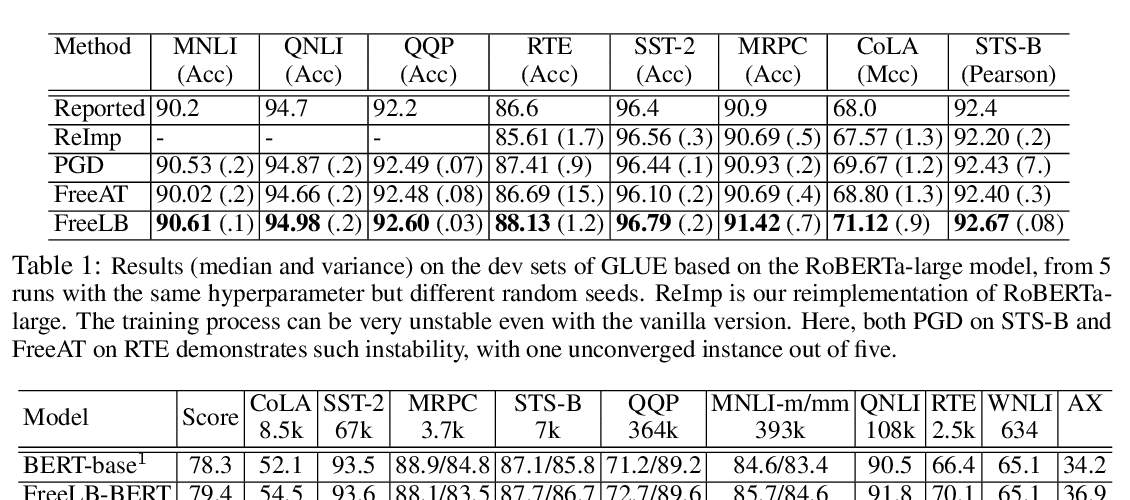
FreeLB: Enhanced Adversarial Training for Natural Language Understanding
Chen Zhu, Yu Cheng, Zhe Gan, Siqi Sun, Tom Goldstein, Jingjing Liu,
A Latent Morphology Model for Open-Vocabulary Neural Machine Translation
Duygu Ataman, Wilker Aziz, Alexandra Birch,
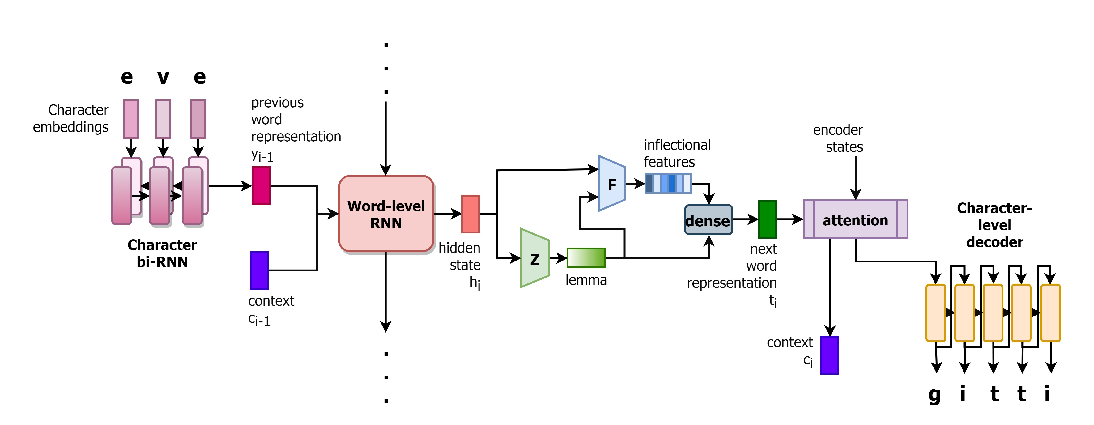
Neural Machine Translation with Universal Visual Representation
Zhuosheng Zhang, Kehai Chen, Rui Wang, Masao Utiyama, Eiichiro Sumita, Zuchao Li, Hai Zhao,

Sequential Latent Knowledge Selection for Knowledge-Grounded Dialogue
Byeongchang Kim, Jaewoo Ahn, Gunhee Kim,
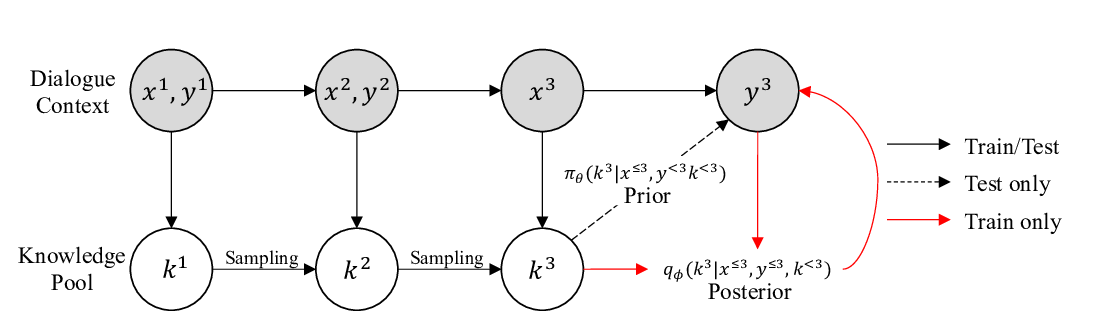
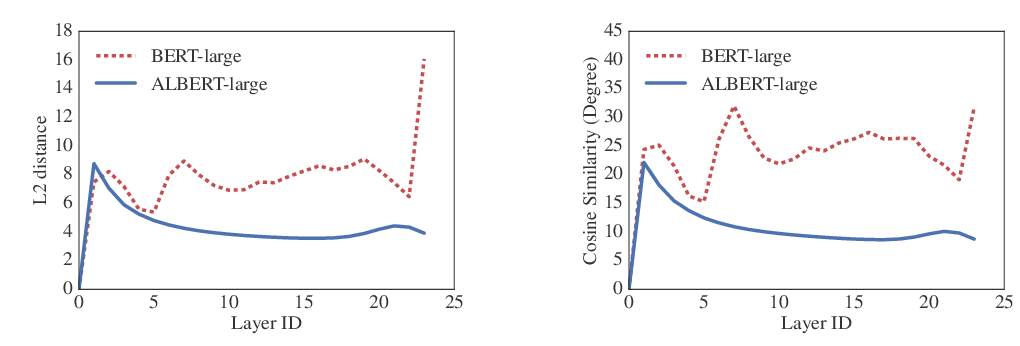
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut,
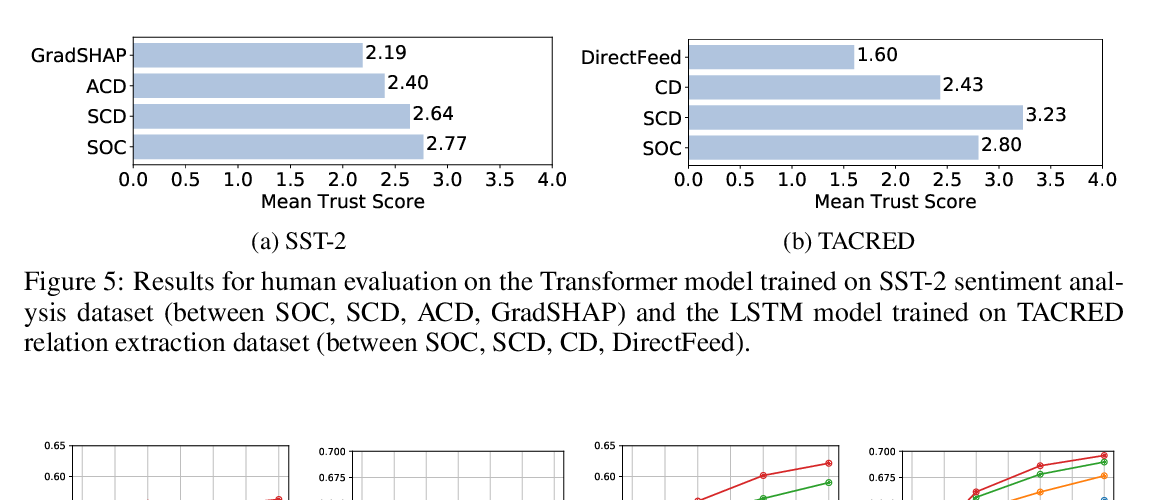
Towards Hierarchical Importance Attribution: Explaining Compositional Semantics for Neural Sequence Models
Xisen Jin, Zhongyu Wei, Junyi Du, Xiangyang Xue, Xiang Ren,
Mirror-Generative Neural Machine Translation
Zaixiang Zheng, Hao Zhou, Shujian Huang, Lei Li, Xin-Yu Dai, Jiajun Chen,
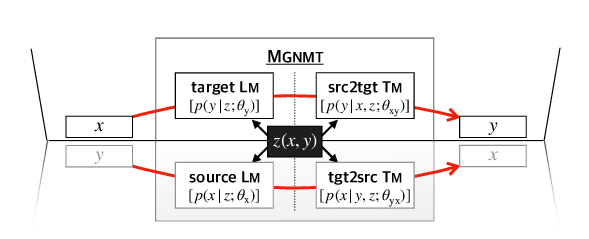
Data-dependent Gaussian Prior Objective for Language Generation
Zuchao Li, Rui Wang, Kehai Chen, Masso Utiyama, Eiichiro Sumita, Zhuosheng Zhang, Hai Zhao,
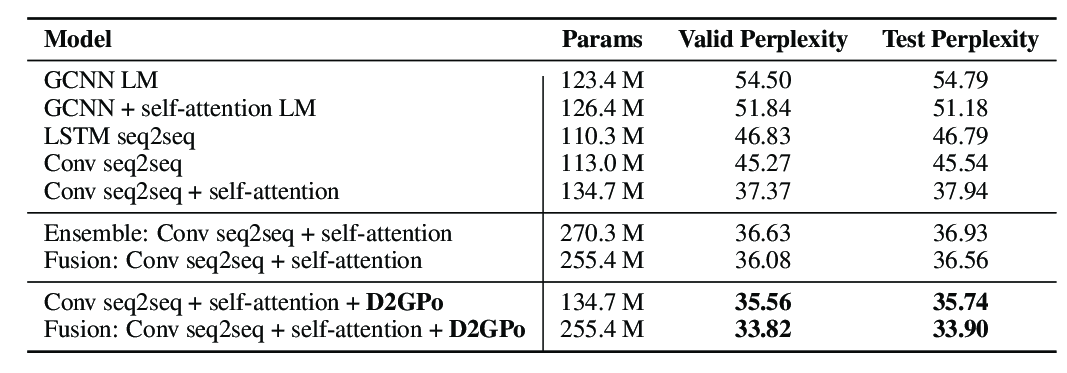
PC-DARTS: Partial Channel Connections for Memory-Efficient Architecture Search
Yuhui Xu, Lingxi Xie, Xiaopeng Zhang, Xin Chen, Guo-Jun Qi, Qi Tian, Hongkai Xiong,
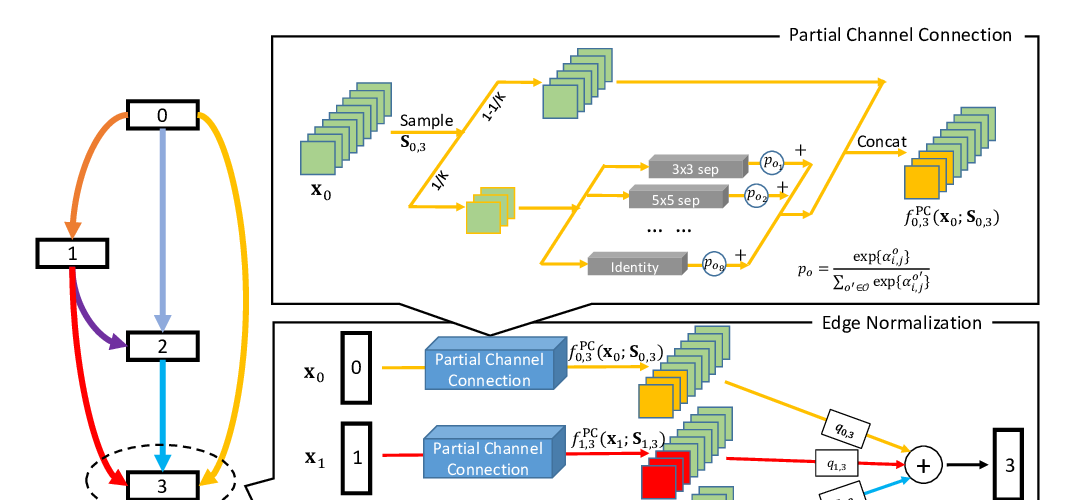
A Signal Propagation Perspective for Pruning Neural Networks at Initialization
Namhoon Lee, Thalaiyasingam Ajanthan, Stephen Gould, Philip H. S. Torr,
Network Deconvolution
Chengxi Ye, Matthew Evanusa, Hua He, Anton Mitrokhin, Tom Goldstein, James A. Yorke, Cornelia Fermuller, Yiannis Aloimonos,

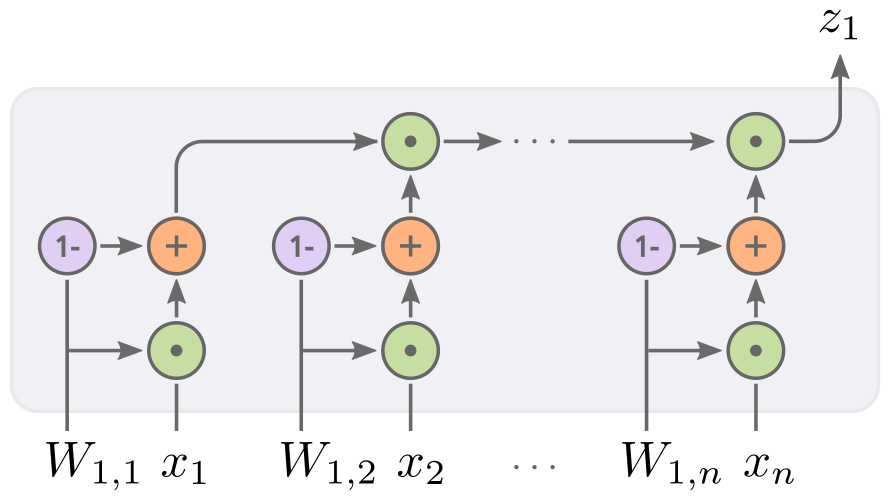
And the Bit Goes Down: Revisiting the Quantization of Neural Networks
Pierre Stock, Armand Joulin, Rémi Gribonval, Benjamin Graham, Hervé Jégou,
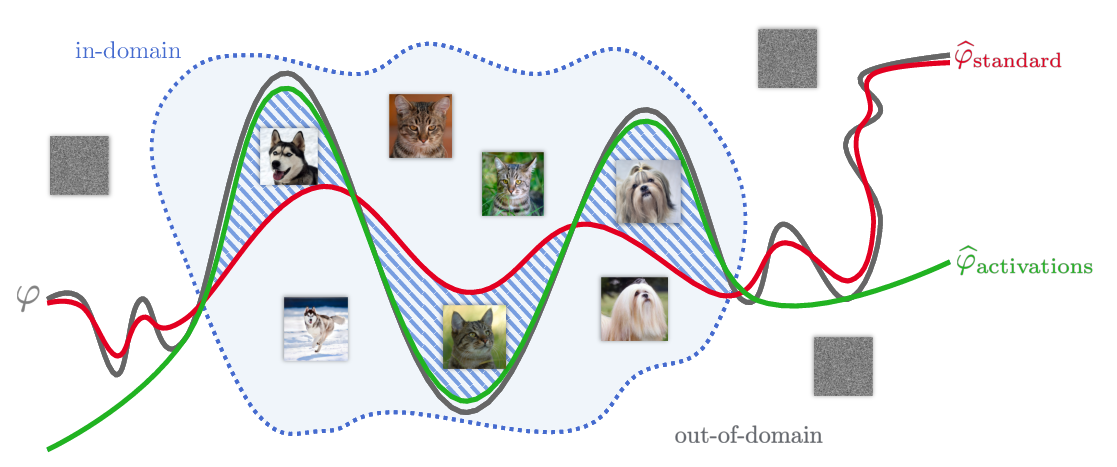

Understanding and Robustifying Differentiable Architecture Search
Arber Zela, Thomas Elsken, Tonmoy Saikia, Yassine Marrakchi, Thomas Brox, Frank Hutter,
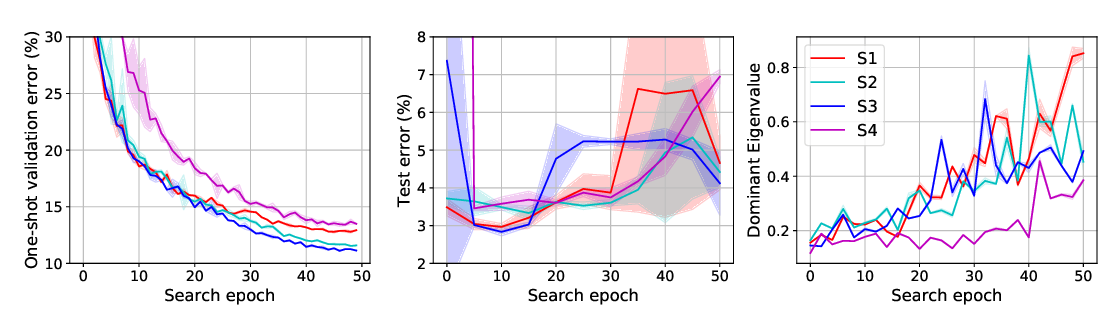
Comparing Rewinding and Fine-tuning in Neural Network Pruning
Alex Renda, Jonathan Frankle, Michael Carbin,
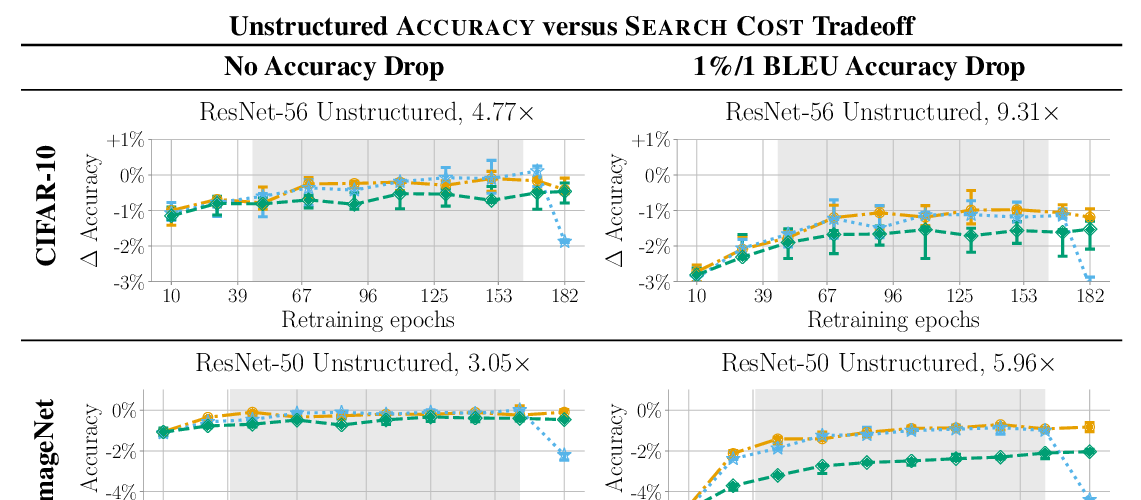
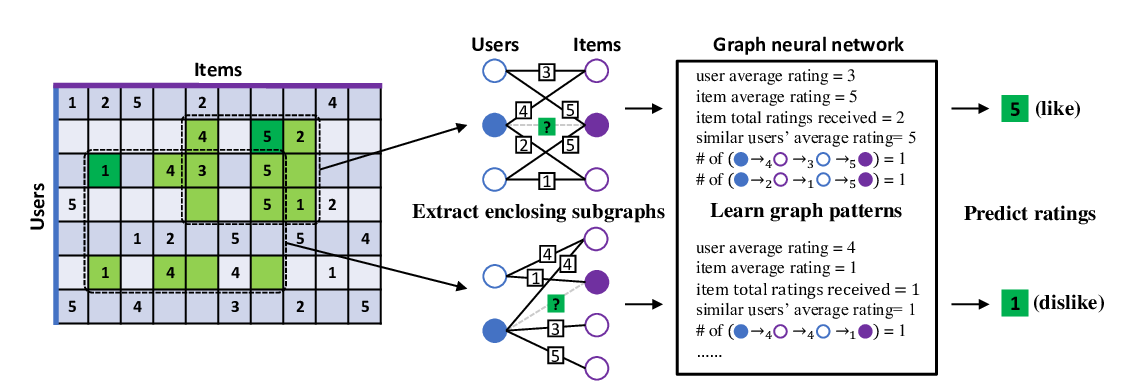
Geom-GCN: Geometric Graph Convolutional Networks
Hongbin Pei, Bingzhe Wei, Kevin Chen-Chuan Chang, Yu Lei, Bo Yang,
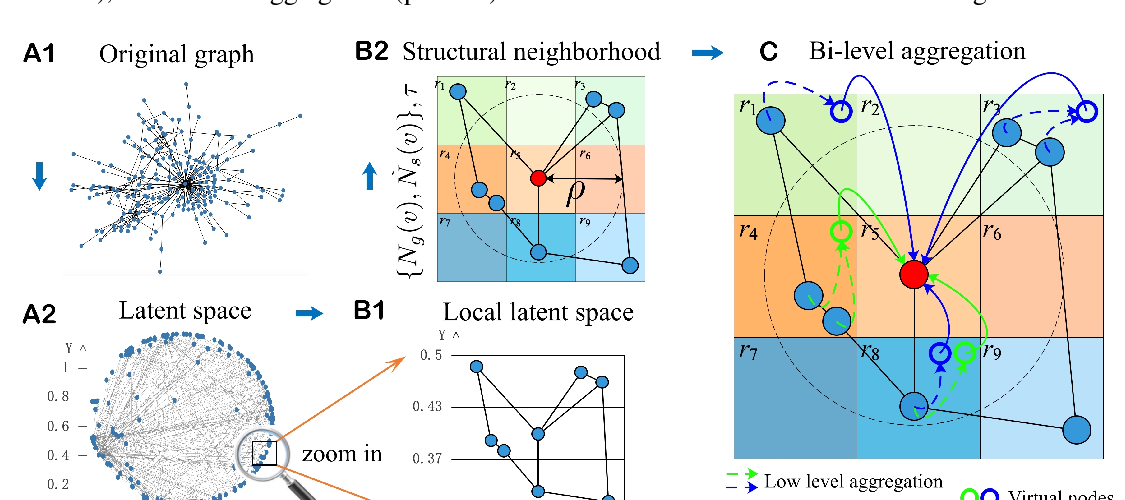
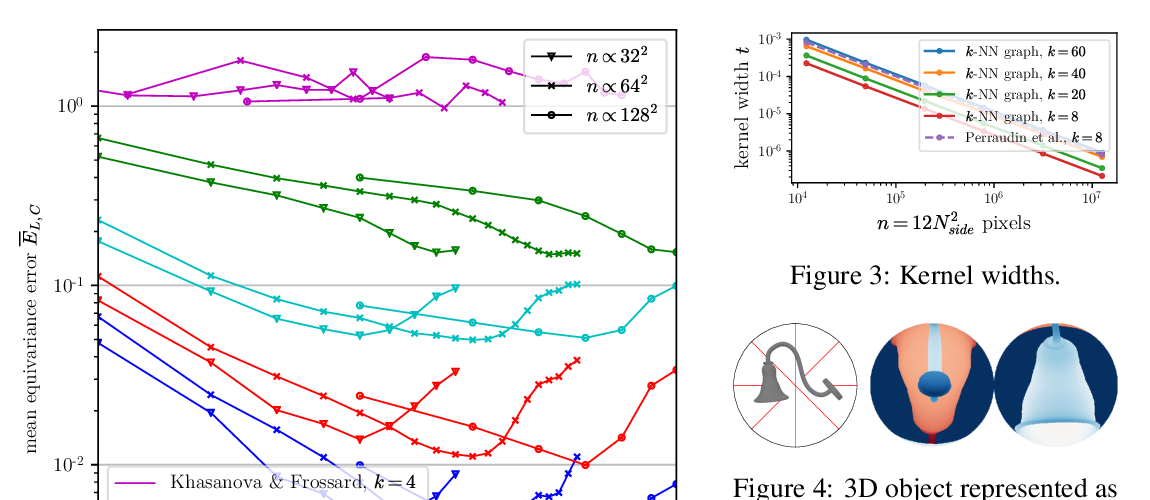
DeepSphere: a graph-based spherical CNN
Michaël Defferrard, Martino Milani, Frédérick Gusset, Nathanaël Perraudin,
The Logical Expressiveness of Graph Neural Networks
Pablo Barceló, Egor V. Kostylev, Mikael Monet, Jorge Pérez, Juan Reutter, Juan Pablo Silva,

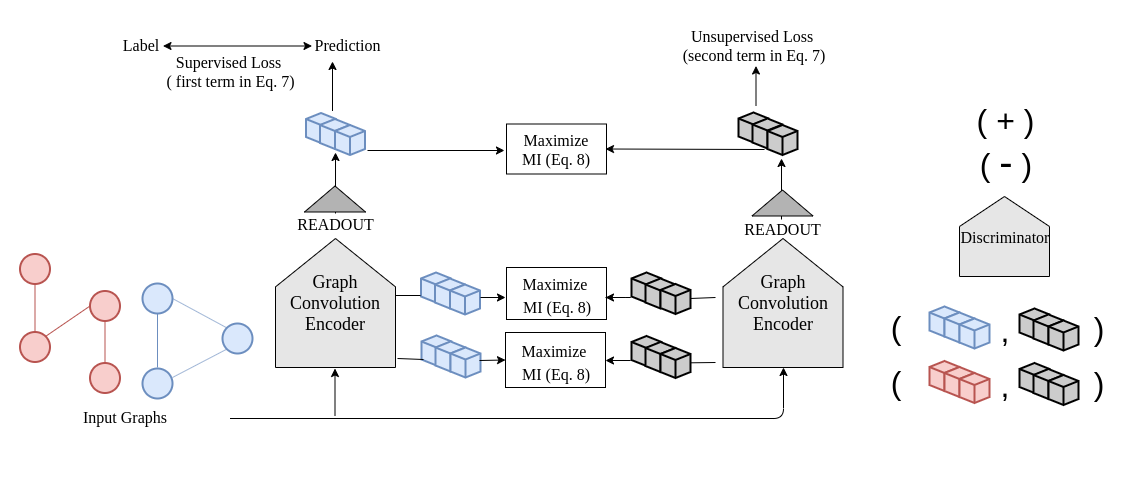
InfoGraph: Unsupervised and Semi-supervised Graph-Level Representation Learning via Mutual Information Maximization
Fan-Yun Sun, Jordan Hoffman, Vikas Verma, Jian Tang,
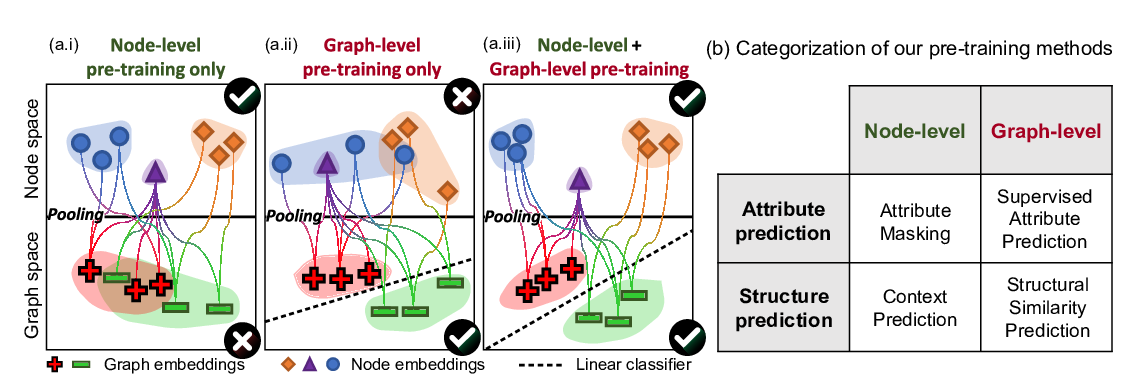
Strategies for Pre-training Graph Neural Networks
Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay Pande, Jure Leskovec,
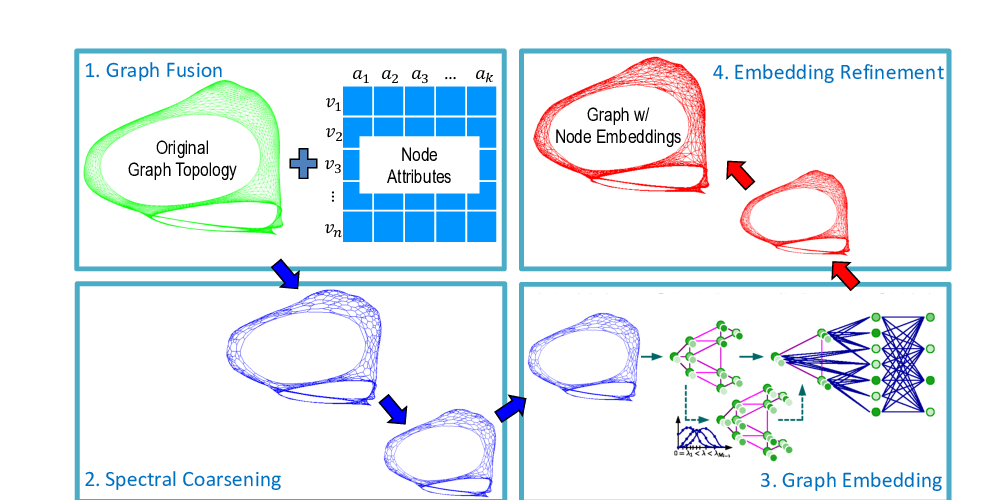
GraphZoom: A Multi-level Spectral Approach for Accurate and Scalable Graph Embedding
Chenhui Deng, Zhiqiang Zhao, Yongyu Wang, Zhiru Zhang, Zhuo Feng,
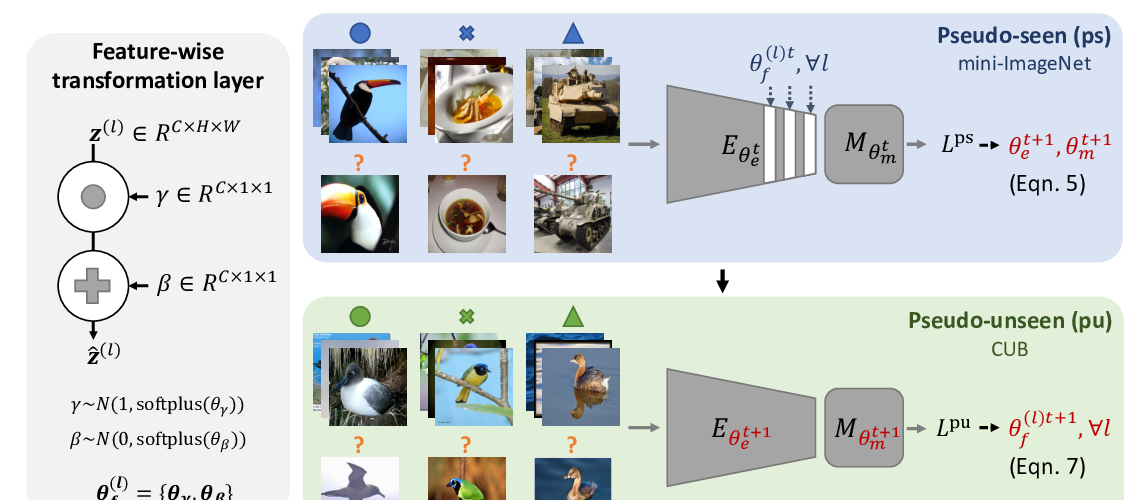
Cross-Domain Few-Shot Classification via Learned Feature-Wise Transformation
Hung-Yu Tseng, Hsin-Ying Lee, Jia-Bin Huang, Ming-Hsuan Yang,
Sliced Cramer Synaptic Consolidation for Preserving Deeply Learned Representations
Soheil Kolouri, Nicholas A. Ketz, Andrea Soltoggio, Praveen K. Pilly,

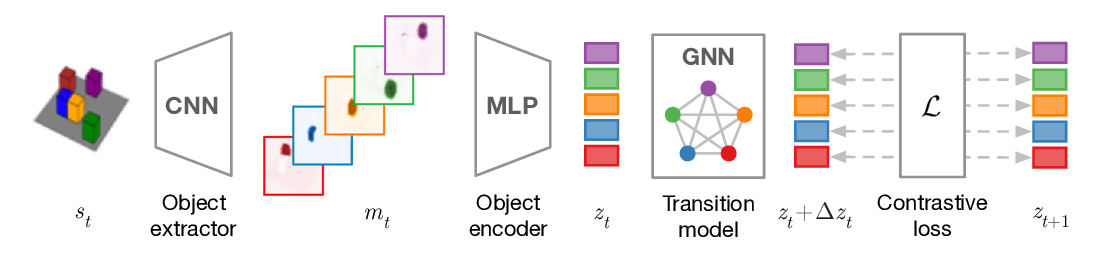
Continual learning with hypernetworks
Johannes von Oswald, Christian Henning, João Sacramento, Benjamin F. Grewe,

Fast Task Inference with Variational Intrinsic Successor Features
Steven Hansen, Will Dabney, Andre Barreto, David Warde-Farley, Tom Van de Wiele, Volodymyr Mnih,
Dynamics-Aware Unsupervised Skill Discovery
Archit Sharma, Shixiang Gu, Sergey Levine, Vikash Kumar, Karol Hausman,

Continual learning with hypernetworks
Johannes von Oswald, Christian Henning, João Sacramento, Benjamin F. Grewe,
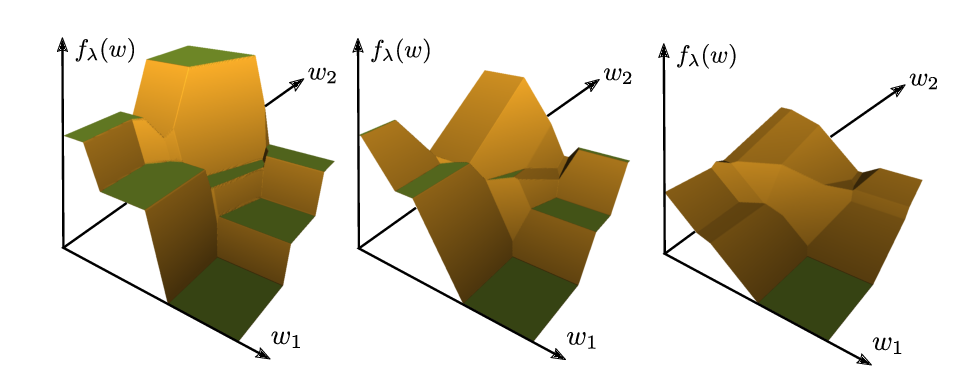
The Break-Even Point on Optimization Trajectories of Deep Neural Networks
Stanislaw Jastrzebski, Maciej Szymczak, Stanislav Fort, Devansh Arpit, Jacek Tabor, Kyunghyun Cho, Krzysztof Geras,
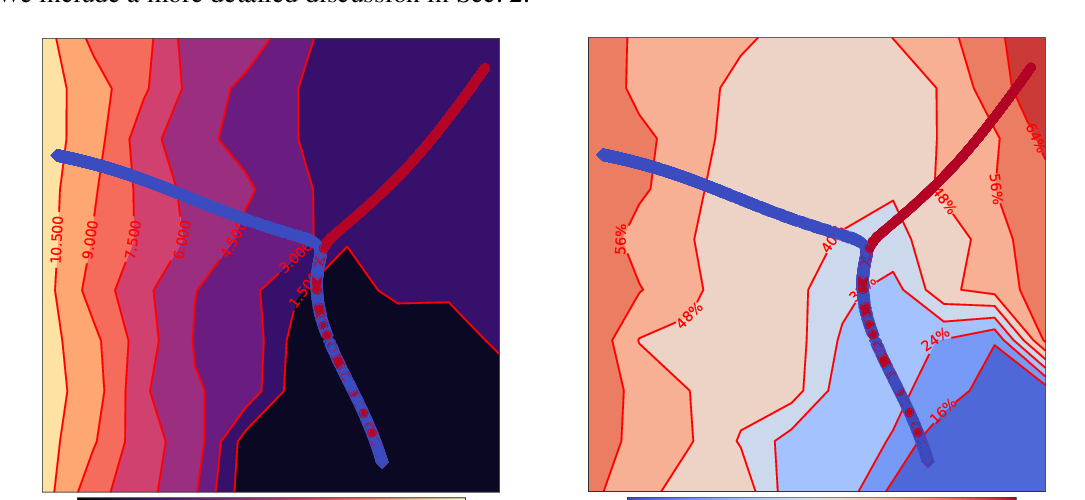
Differentiation of Blackbox Combinatorial Solvers
Marin Vlastelica Pogančić, Anselm Paulus, Vit Musil, Georg Martius, Michal Rolinek,
Differentiable Reasoning over a Virtual Knowledge Base
Bhuwan Dhingra, Manzil Zaheer, Vidhisha Balachandran, Graham Neubig, Ruslan Salakhutdinov, William W. Cohen,
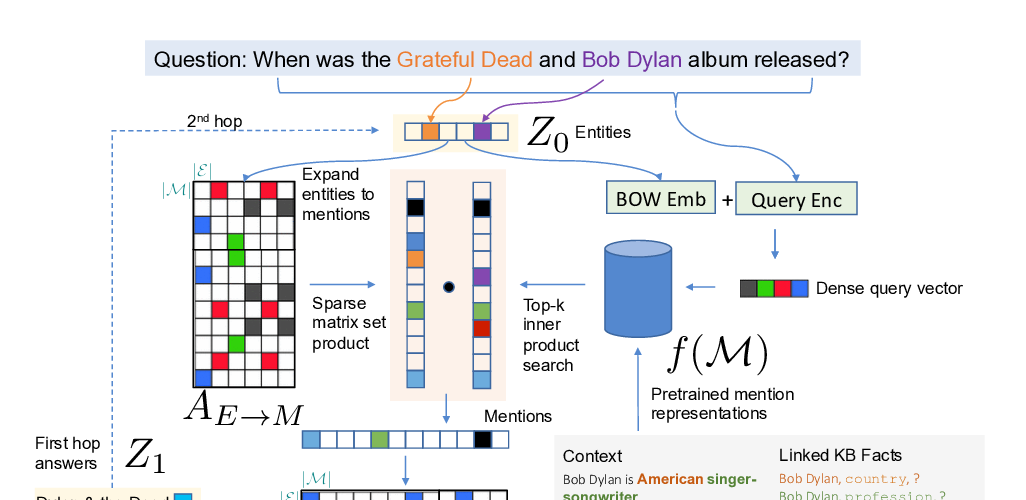
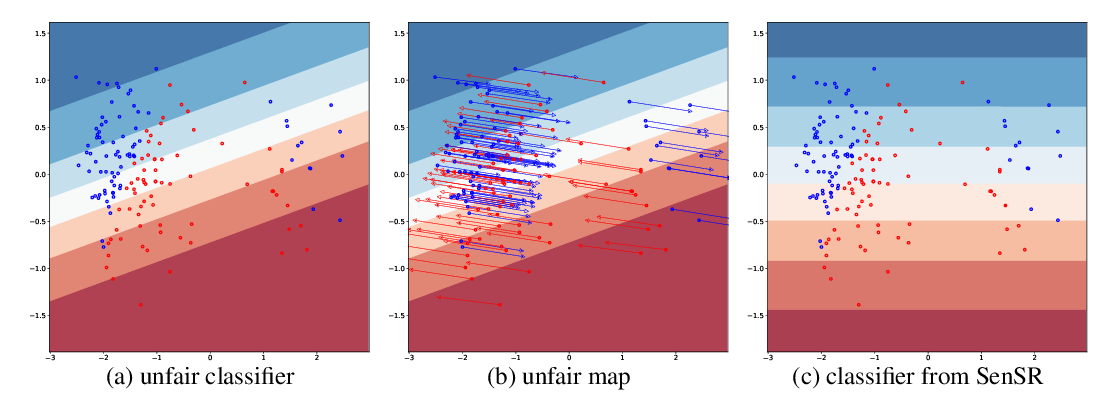
Training individually fair ML models with sensitive subspace robustness
Mikhail Yurochkin, Amanda Bower, Yuekai Sun,
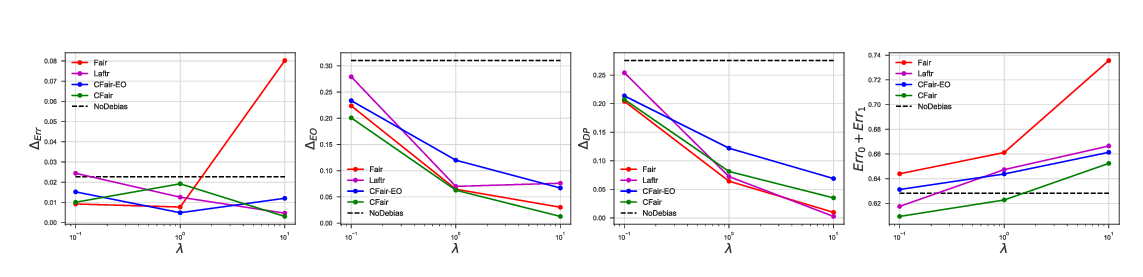
Conditional Learning of Fair Representations
Han Zhao, Amanda Coston, Tameem Adel, Geoffrey J. Gordon,
Explanation by Progressive Exaggeration
Sumedha Singla, Brian Pollack, Junxiang Chen, Kayhan Batmanghelich,

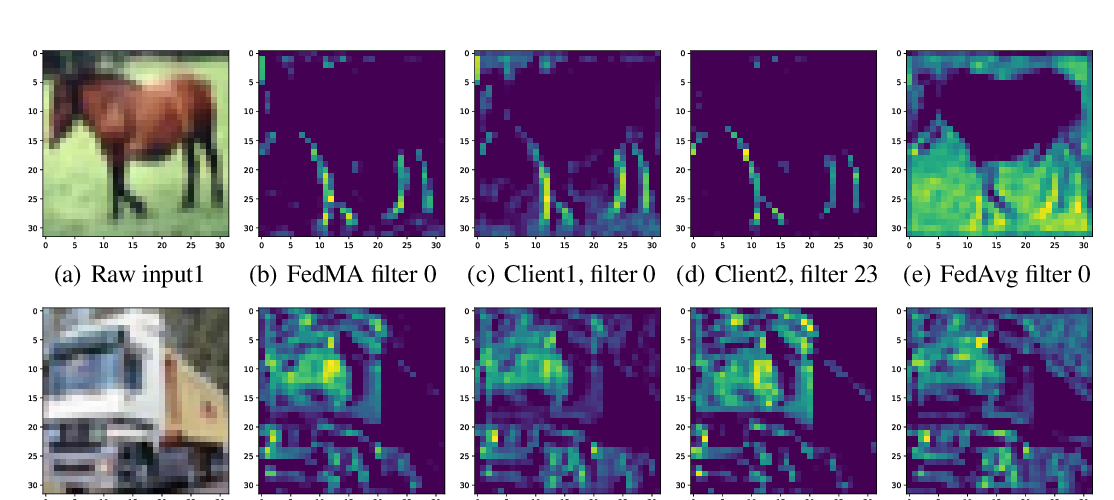
Federated Learning with Matched Averaging
Hongyi Wang, Mikhail Yurochkin, Yuekai Sun, Dimitris Papailiopoulos, Yasaman Khazaeni,
Expos
Code of Conduct
The open exchange of ideas, the freedom of thought and expression, and respectful scientific debate are central to the goals of this conference on machine learning; this requires a community and an environment that recognizes and respects the inherent worth of every person.
Who
All participants---attendees, organizers, reviewers, speakers, sponsors, and volunteers at our conference, workshops, and conference-sponsored social events---are required to agree with this Code of Conduct both during the event and on official communication channels, including social media. Organizers will enforce this code, and we expect cooperation from all participants to help ensure a safe and productive environment for everybody.
Scope
The conference commits itself to provide an experience for all participants that is free from harassment, bullying, discrimination, and retaliation. This includes offensive comments related to gender, gender identity and expression, age, sexual orientation, disability, physical appearance, body size, race, ethnicity, religion (or lack thereof), politics, technology choices, or any other personal characteristics. Bullying, intimidation, personal attacks, harassment, sustained disruption of talks or other events, and behavior that interferes with another participant's full participation will not be tolerated. This includes sexual harassment, stalking, following, harassing photography or recording, inappropriate physical contact, unwelcome sexual attention, public vulgar exchanges, and diminutive characterizations, which are all unwelcome in this community.
The expected behaviour in line with the scope above extends to any format of the conference, including any virtual forms, and to the use of any online tools related to the conference. These include comments on OpenReview within or outside of reviewing periods, conference-wide chat tools, Q&A tools, live stream interactions, and any other forms of virtual interaction. Trolling, use of inappropriate imagery or videos, offensive language either written or in-person over video or audio, unwarranted direct messages (DMs), and extensions of such behaviour to tools outside those used by the conference but related to the conference, its program and attendees, are not allowed. In addition, doxxing or revealing any personal information to target any participant will not be tolerated.
Sponsors are equally subject to this Code of Conduct. In particular, sponsors should not use images, activities, or other materials that are of a sexual, racial, or otherwise offensive nature. Sponsor representatives and staff (including volunteers) should not use sexualized clothing/uniforms/costumes or otherwise create a sexualized environment. This code applies both to official sponsors as well as any organization that uses the conference name as branding as part of its activities at or around the conference.
Outcomes
Participants asked by any member of the community to stop any such behavior are expected to comply immediately. If a participant engages in such behavior, the conference organizers may take any action they deem appropriate, including: a formal or informal warning to the offender, expulsion from the conference (either physical expulsion, or termination of access codes) with no refund, barring from participation in future conferences or their organization, reporting the incident to the offender’s local institution or funding agencies, or reporting the incident to local law enforcement. A response of "just joking" will not be accepted; behavior can be harassing without an intent to offend. If action is taken, an appeals process will be made available.
Reporting
If you have concerns related to your inclusion at that conference, or observe someone else's difficulties, or have any other concerns related to inclusion, please email our ICLR Hotline. For online events and tools, there are options to directly report specific chat/text comments, in addition to the above reporting. Complaints and violations will be handled with discretion. Reports made during the conference will be responded to within 24 hours; those at other times in less than two weeks. We are prepared and eager to help participants contact relevant help services, to escort them to a safe location, or to otherwise assist those experiencing harassment to feel safe for the duration of the conference. We gratefully accept feedback from the community on policy and actions; please contact us.