Four Things Everyone Should Know to Improve Batch Normalization
Cecilia Summers, Michael J. Dinneen,
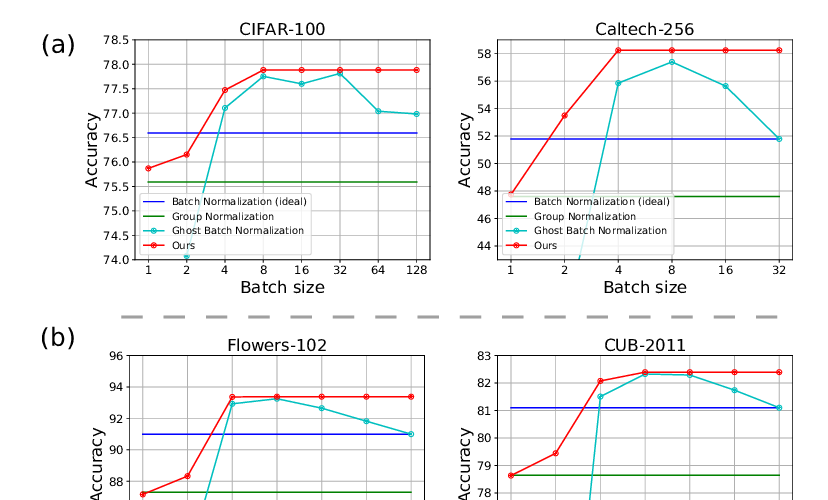

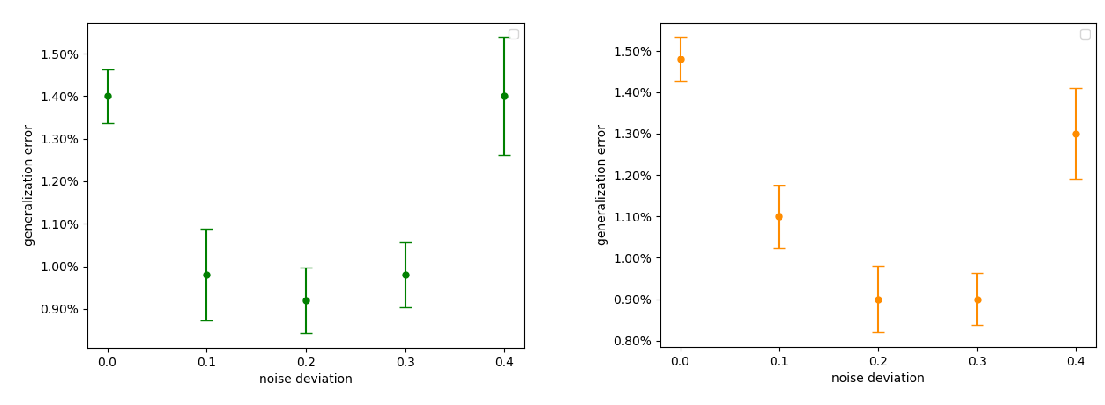
Piecewise linear activations substantially shape the loss surfaces of neural networks
Fengxiang He, Bohan Wang, Dacheng Tao,
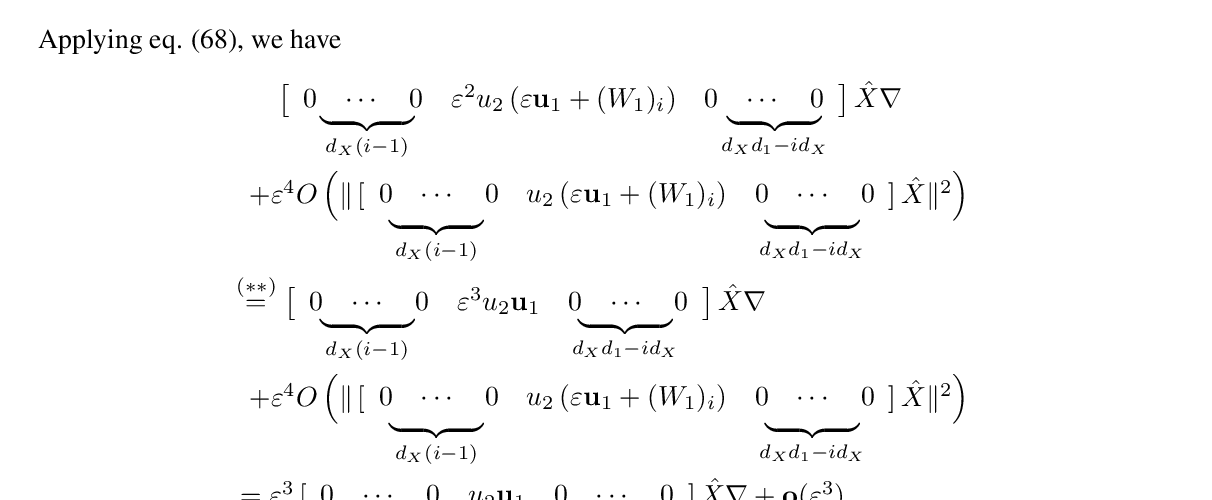
Keywords: batch normalization, deep learning theory, generalization, loss landscape, neural tangent kernel, robustness