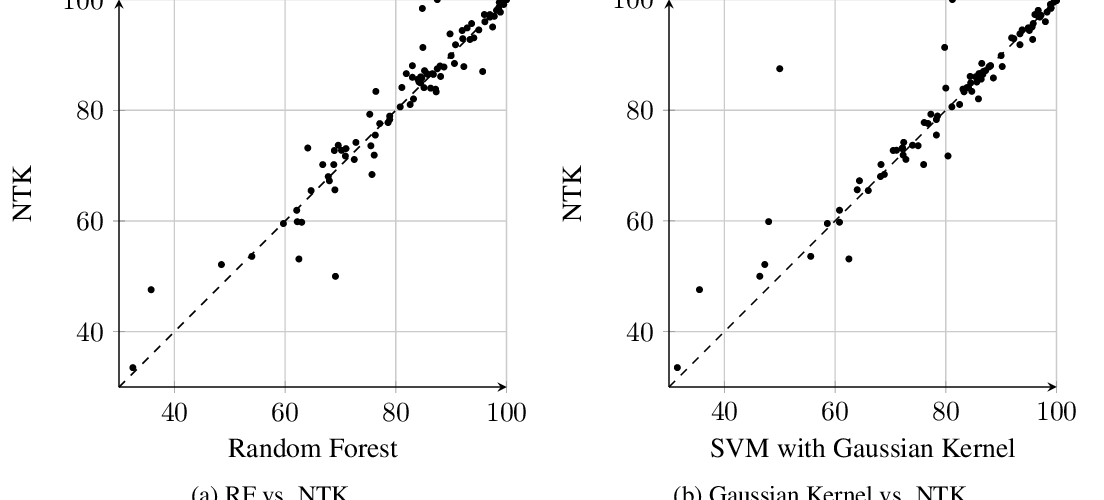
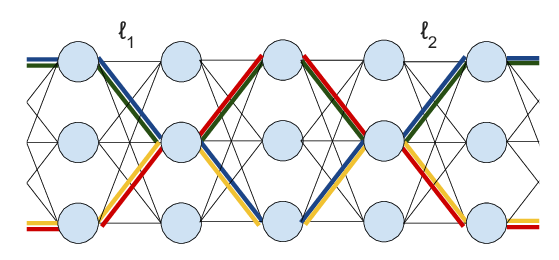
Harnessing the Power of Infinitely Wide Deep Nets on Small-data Tasks
Sanjeev Arora, Simon S. Du, Zhiyuan Li, Ruslan Salakhutdinov, Ruosong Wang, Dingli Yu,

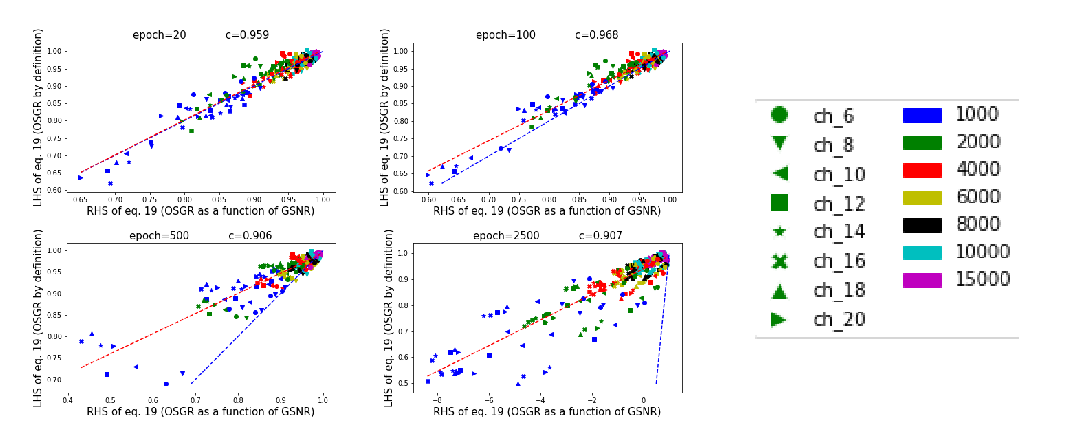
Understanding Why Neural Networks Generalize Well Through GSNR of Parameters
Jinlong Liu, Yunzhi Bai, Guoqing Jiang, Ting Chen, Huayan Wang,