Abstract:
We consider the challenge of estimating treatment effects from observational data; and point out that, in general, only some factors based on the observed covariates X contribute to selection of the treatment T, and only some to determining the outcomes Y. We model this by considering three underlying sources of {X, T, Y} and show that explicitly modeling these sources offers great insight to guide designing models that better handle selection bias. This paper is an attempt to conceptualize this line of thought and provide a path to explore it further.
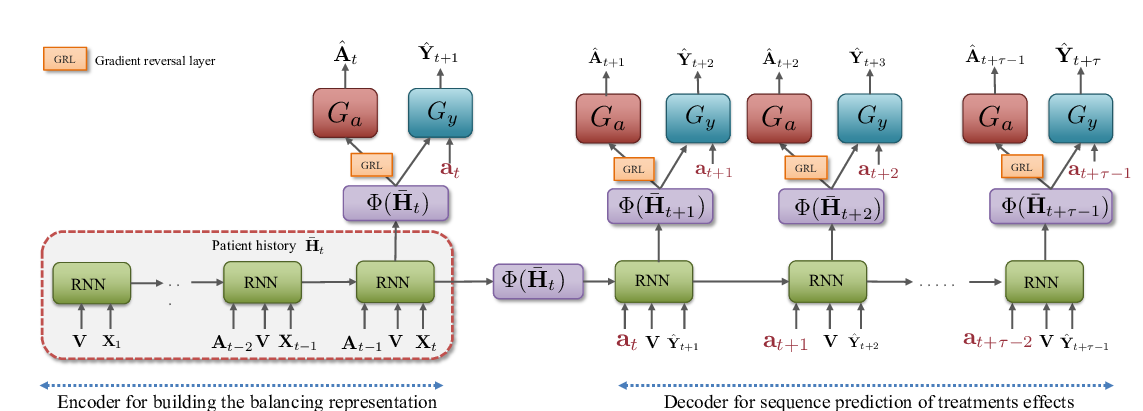
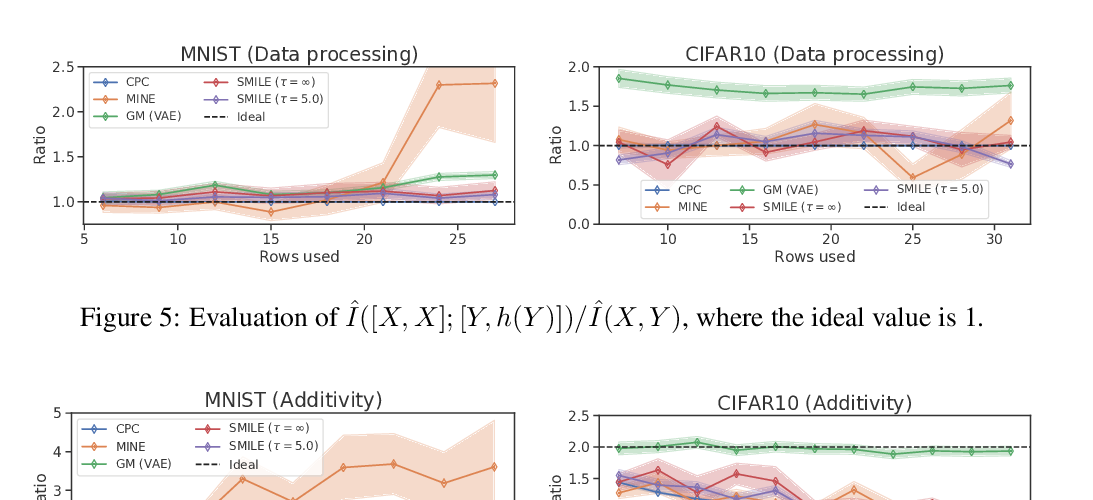
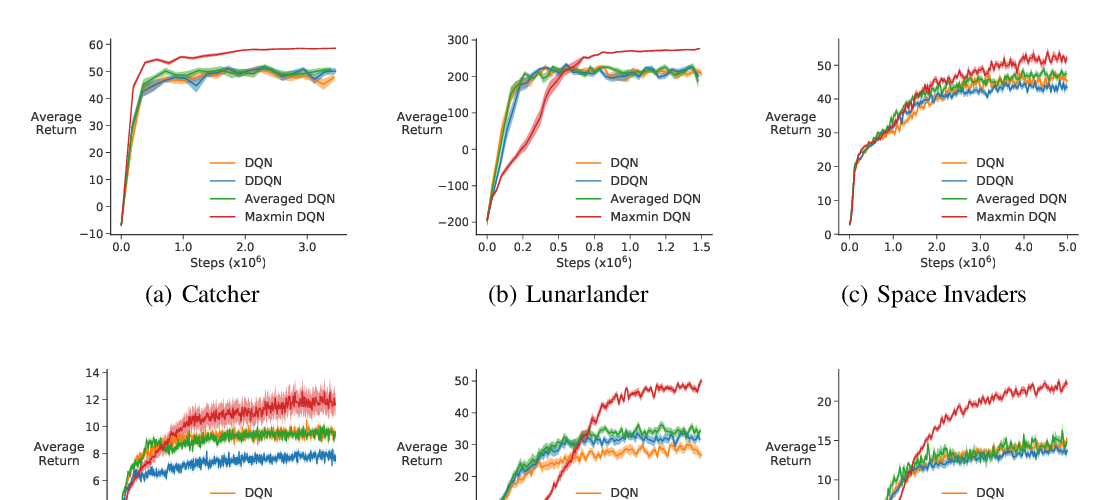
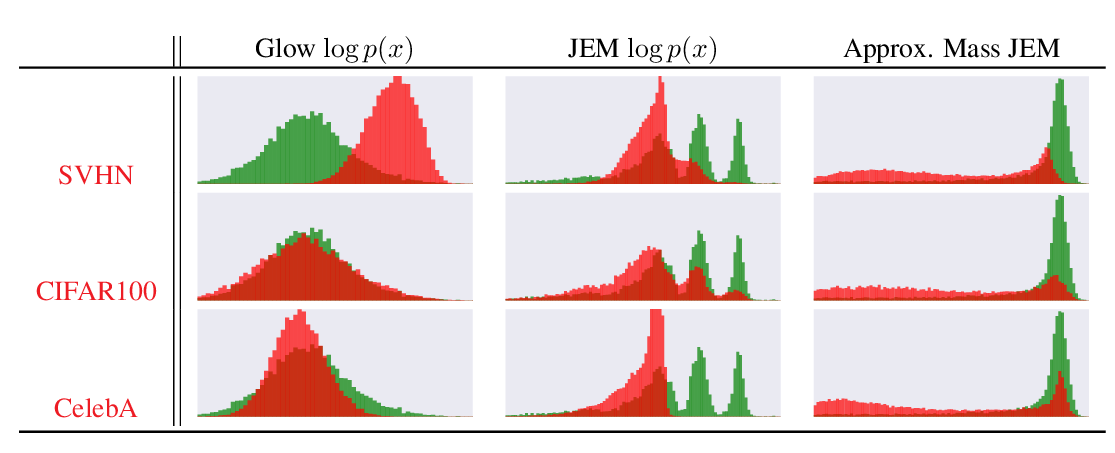
In this work, we propose an algorithm to (1) identify disentangled representations of the above-mentioned underlying factors from any given observational dataset D and (2) leverage this knowledge to reduce, as well as account for, the negative impact of selection bias on estimating the treatment effects from D. Our empirical results show that the proposed method achieves state-of-the-art performance in both individual and population based evaluation measures.