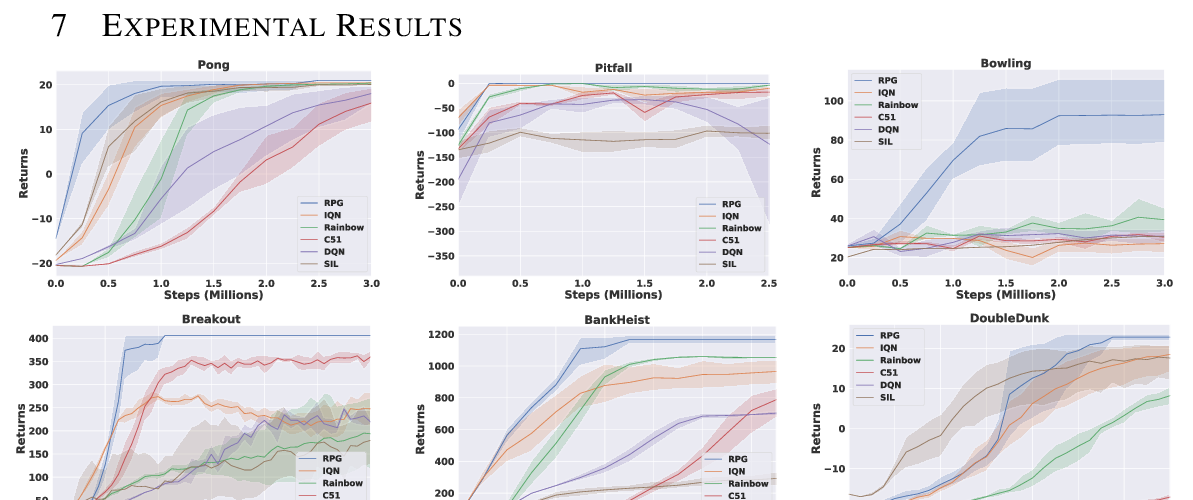
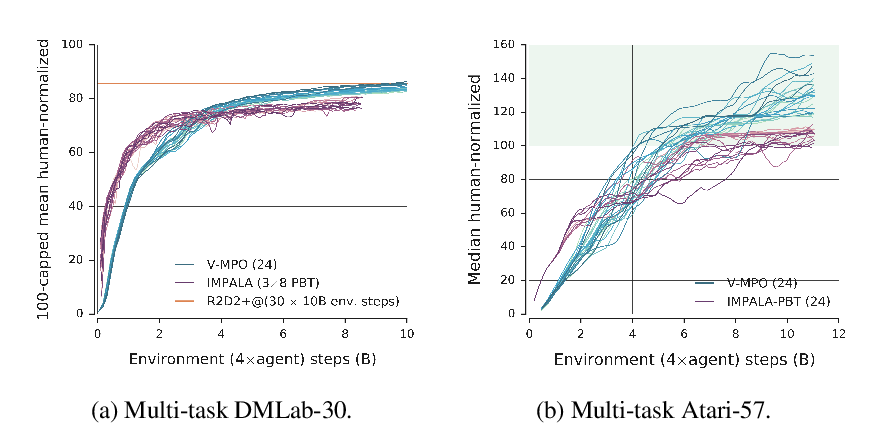
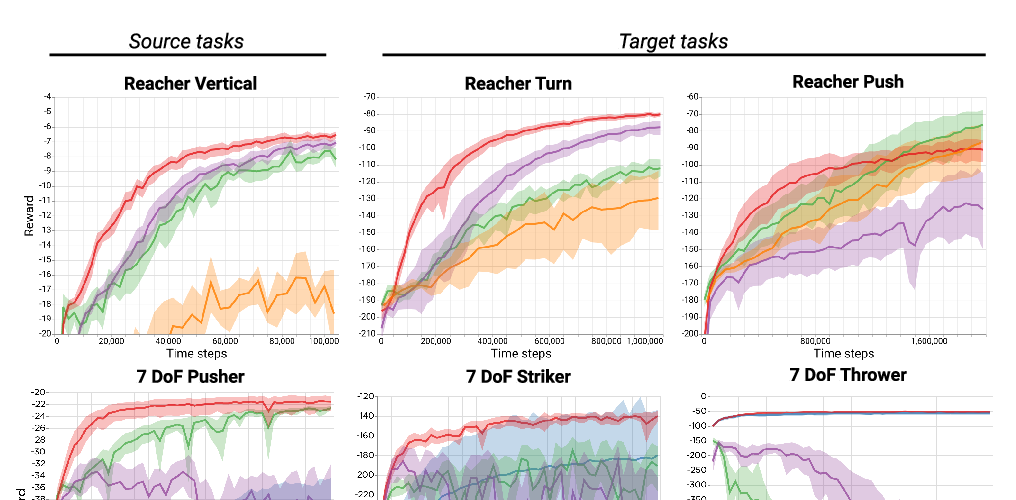
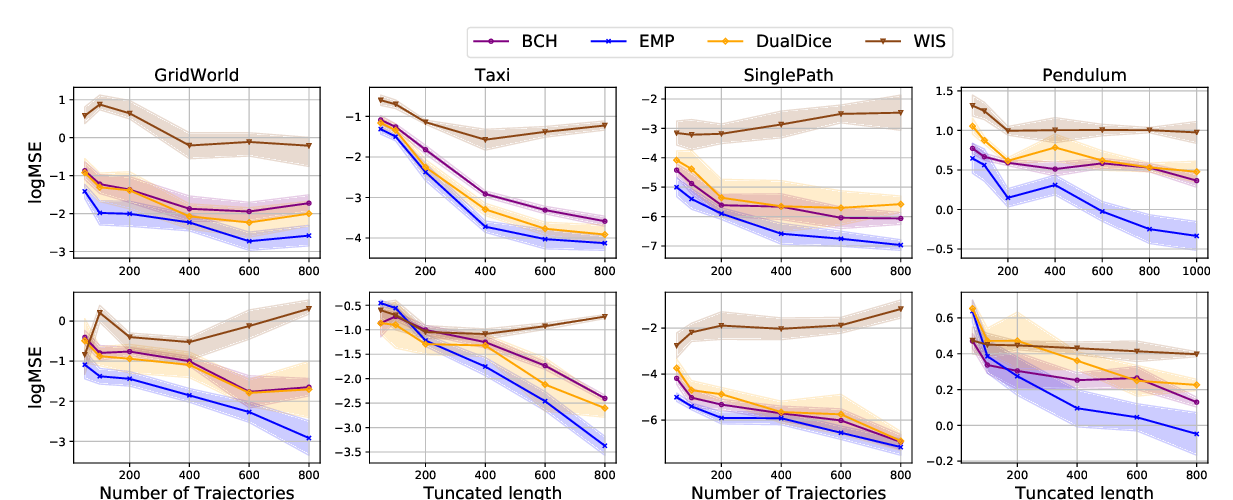
Abstract:
Model-based reinforcement learning (MBRL) with model-predictive control or
online planning has shown great potential for locomotion control tasks in both
sample efficiency and asymptotic performance. Despite the successes, the existing
planning methods search from candidate sequences randomly generated in the
action space, which is inefficient in complex high-dimensional environments. In
this paper, we propose a novel MBRL algorithm, model-based policy planning
(POPLIN), that combines policy networks with online planning. More specifically,
we formulate action planning at each time-step as an optimization problem using
neural networks. We experiment with both optimization w.r.t. the action sequences
initialized from the policy network, and also online optimization directly w.r.t. the
parameters of the policy network. We show that POPLIN obtains state-of-the-art
performance in the MuJoCo benchmarking environments, being about 3x more
sample efficient than the state-of-the-art algorithms, such as PETS, TD3 and SAC.
To explain the effectiveness of our algorithm, we show that the optimization surface
in parameter space is smoother than in action space. Further more, we found the
distilled policy network can be effectively applied without the expansive model
predictive control during test time for some environments such as Cheetah. Code
is released.